
Abstract
This review focuses on positron emission tomography (PET) imaging algorithms and traces the evolution of PET image reconstruction methods. First, we provide an overview of conventional PET image reconstruction methods from filtered backprojection through to recent iterative PET image reconstruction algorithms, and then review deep learning methods for PET data up to the latest innovations within three main categories. The first category involves post-processing methods for PET image denoising. The second category comprises direct image reconstruction methods that learn mappings from sinograms to the reconstructed images in an end-to-end manner. The third category comprises iterative reconstruction methods that combine conventional iterative image reconstruction with neural-network enhancement. We discuss future perspectives on PET imaging and deep learning technology.
Similar content being viewed by others
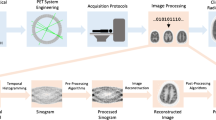


1 Introduction
Deep learning has been a popular topic in the scientific communities for a long time due to its significant impact in many fields [1,2,3]. A new wave of deep learning has been sweeping the medical imaging field [4,5,6,7,8,9,10], and some deep learning techniques, such as image reconstruction and computer-aided diagnosis, have already been implemented in commercial systems [11,12,13,14]. In this review, we focus on positron emission tomography (PET) imaging using deep learning in the field of medical imaging [15,16,17,18,19,20,21,22,23,24].
PET is a molecular imaging method for visualizing and quantifying the distribution of radioactive tracers labeled with positron-emitting radioisotopes, such as fluorine-18 (18F), oxygen-15 (15O), nitrogen-13 (13N), and carbon-11 (11C), administered to living human participants [25]. Thus, PET can observe tracer kinetics; therefore, it is used not only for cancer diagnosis [26, 27] and diagnosis of neurodegenerative diseases, such as Alzheimer's disease [28, 29], but for fundamental research, such as brain function [30, 31]. PET is a unique imaging modality capable of tracking picomole-order molecules; however, image noise is severe compared to other tomographic scanners, such as X-ray computed tomography (CT) because there are fewer counts in the measured data. Image noise degrades quantitative accuracy and lesion detectability, leading to the potential scenario of missed lesions. One straightforward strategy for improving PET image quality (or suppressing PET image noise) is to increase the amount of PET tracer administered to the individual. This is sometimes difficult to actively adopt because of the problem of increased radiation exposure [32] and the limitations in count-rate capabilities of PET scanners. Therefore, there is a demand for noise reduction techniques that do not increase injected dose. It is no exaggeration to state that the development history of PET imaging has been a battle against noise.
In this review, we highlight the algorithms used for PET imaging and systematically describe the history of PET image reconstruction and post-processing denoising algorithms from early analytical methods to the latest advances in deep learning technology. Section 2 describes the basic principles of PET imaging, including PET imaging models, conventional analytical and statistical PET image reconstruction algorithms, and an overview of deep learning-based PET imaging algorithms. Section 3 reviews deep learning for PET image denoising algorithms, and Sects. 4, 5, and 6 review deep learning for direct, iterative, and dynamic PET image reconstruction algorithms, respectively. Finally, we conclude this review by providing future perspectives on PET imaging and deep learning technology.
2 Basic principles of PET imaging
This section briefly reviews the history of PET image reconstruction prior to the advent of deep learning techniques. Figure 1 summarizes the evolution of PET image reconstruction between the 1980s and 2000s.

Demonstration of various PET image reconstruction algorithms from the FBP to recent iterative PET image reconstruction algorithms, which were applied to the same simulation data generated from the BrainWeb (https://brainweb.bic.mni.mcgill.ca/brainweb/)
Between the 1970s and 1980s, researchers developed analytical reconstruction methods, such as the filtered backprojection (FBP) algorithm for tomographic imaging systems, such as X-ray CT and PET [33,34,35]. FBP is an analytical method that models the relationship between the image and the tomographic measurement data through an integral equation [36] as follows:
where \(X\left(u,v\right)\) is a two-dimensional (2D) image and \(Y\left(r,\phi \right)\) holds 1D projections for each view angles, known as a sinogram. The sinogram is an integral along the \(s\)-axis of a rotated image by an angle \(\phi\). This integral transformation is known as the Radon transform [37] or X-ray transform. The principle behind FBP is the projection slice theorem that shows the relationship between the 2D Fourier transform of \(X\left(u,v\right)\) and the 1D Fourier transform of \(Y\left(r,\phi \right)\), with respect to r as a one-to-one mapping. The most commonly used analytical method is FBP, which is calculated as follows:
where \(i\) is the imaginary unit, \(\xi\) is the frequency domain variable, and the high pass filter \(\left|\xi \right|\) is called a ramp filter. Although the ramp filter is an analytically derived necessity, enhancing the high-frequency components tends to produce severe noise. Therefore, frequency cutoff techniques and various filters have been developed to reduce high-frequency noise, although they sacrifice spatial resolution. In principle, the analytical method is known for its high speed, linearity, and quantitative accuracy; however, it is susceptible to noise and leads to streak artifacts in low-count situations, as shown in Fig. 1.
Early PET systems had septa inserted between detector rings to shield gamma rays from oblique directions, and measured data to be processed were limited to a 2D plane. In the 1980s, researchers developed 3D PET image reconstruction methods [38,39,40], and since the 1990s, 3D acquisition has been performed by removing the septa or making them retractable and switchable for 2D and 3D modes [41, 42]. While projections in a range of 0 to 180° for the directions perpendicular to the axial direction form a complete set for reconstruction of a 3D image, the 3D acquisition significantly improved the sensitivity by measuring oblique projections. To fully utilize 3D projection data, image reconstruction methods that consider data redundancy are required. We should note that, in addition, scatter correction is essential for quantification due to the increased scatter components in 3D projection data, contrary to the 2D acquisition where the septa shield most components scattered inside a patient's body. Scatter components are estimated and subtracted from projection data before analytical image reconstruction. There are many studies regarding the estimation and the impact of the scatter [43,44,45,46,47,48,49], but they are out of the scope of this article. One of the most used analytical image reconstruction methods for the 3D PET is the 3D reprojection (3DRP) algorithm [39], which includes estimating the missing truncated data in 2D projections in order to apply 3D FBP. The 3D FBP is an extension of 2D FBP to three dimensions, where the Colsher filter [38] is applied to 2D parallel projections for each projection direction parameterized by azimuthal (phi) and co-polar (theta) angles. Note that the set of 2D parallel projections for the co-polar (oblique) angle of 0 is equivalent to the stack of sinograms for 2D FBP (direct sinograms). Then, the filtered 2D parallel projections are back-projected to the image domain. Although the 3D FBP requires projection data without truncation, projections in oblique angles have unmeasured regions against objects inside cylindrical PET scanners. The truncated data are estimated from a 3D image reconstructed as a stack of 2D images by 2D FBP for direct sinograms. The 3DRP method of directly treating 3D projection data was a computational burden for computers in the early 1990s. Therefore, the Fourier rebinning (FORE) method [50, 51] was developed for rebinning 3D projection data to a stack of 2D sinograms, allowing decomposition of the 3D image reconstruction problem into a set of 2D image reconstructions. Not only 2D FBP but iterative 2D image reconstruction methods can be applied following the FORE [52,53,54]. As a result of the maturation of 3D image reconstruction, modern PET scanners no longer use septa. In recent computers, 3D reconstruction methods have become tractable, and even iterative methods are used in practice.
Between the 1980s and 1990s, iterative reconstruction methods, such as the maximum likelihood expectation maximization (MLEM) algorithm [55,56,57], were developed to incorporate statistical and physical models into image reconstruction. In the EM iterative method, the relationship between a tomographic image and measured data is modeled through a system of linear equations and Poisson distribution [58] as follows:
or
where \({\varvec{x}}={\left({x}_{1},{x}_{2},\cdots ,{x}_{J}\right)}^{T}\) is a vector of voxel values of the image, \({\varvec{y}}={\left({y}_{1},{y}_{2},\cdots ,{y}_{I}\right)}^{T}\) is a vector of sampled values of the projection data, \(\overline{{\varvec{b}} }={\left({\overline{b} }_{1},{b}_{2},\cdots ,{\overline{b} }_{I}\right)}^{T}\) is a vector of expected values of background components, such as scatter and random coincidence events, which can be estimated using scatter and randoms modeling methods, and \({\varvec{A}}\in {\mathbb{R}}^{I\times J}\) is a system matrix where each element, and \({a}_{ij},\) is the probability that two gamma rays emitted from \(j\)-th voxel are detected by \(i\)-th line-of-response (LOR). The negative log-likelihood function of data \({\varvec{y}}\) under image \({\varvec{x}}\) is defined as follows:
where \(P\left({\varvec{y}}|{\varvec{x}}\right)\) is the probability of sampling \({\varvec{y}}\) under \({\varvec{x}}\), and \(C\) is a constant. The MLEM algorithm estimates an image by minimizing (5) using iterative updates as follows:
where \(k\) denotes the iteration number. The MLEM algorithm achieves better image quality than the FBP algorithm by leveraging a statistical noise model for PET, as shown in Fig. 1. After introducing the MLEM algorithm, the ordered subset expectation maximization (OSEM) algorithm [59], a block iterative reconstruction method that divides the projection data into subsets and updates the image for each subset, was developed as a speed-up method. Furthermore, Tanaka and Kudo proposed a dynamic row action maximum likelihood (DRAMA) algorithm [60, 61]. The DRAMA algorithm contributes to improved convergence speed in the reconstruction process by controlling an optimal relaxation factor deduced by balancing the noise propagation from each subset to the final reconstructed image [61, 62]. We should note that these algorithms can be also applied for 3D PET data and even time-of-flight (TOF) PET data by properly modeling the system matrix.
Between the 1990s and 2000s, iterative reconstruction methods integrating the point-spread function (PSF) were developed for dedicated PET [63,64,65,66], as well as whole-body PET/CT [67]. The PSF can be modeled in either projection and/or image space. An example of incorporating an image-space PSF is as follows [64]:
where \({\varvec{H}} \in {\mathbb{R}}^{J \times J}\) is a matrix comprising the PSF kernel in the image space. In Eq. (7), the division and multiplication between vectors are element-wise. Note that Eq. (7) is equivalent to Eq. (6) when \({\varvec{H}}\) is identity matrix. The PSF image reconstruction primarily reduces image noise and enhances contrast as well as improves spatial resolution, as shown in Fig. 1. The PSF kernel increases the correlation between voxels and reduces their variance. From this point of view, the image-space PSF can be considered a variant of the basis function approach [68, 69].
Parallel to the development of statistical and physical model-based iterative reconstructions, maximum a posteriori (MAP) reconstruction methods that incorporate image priors, such as smoothness to maximum likelihood estimation, have been developed [63, 70,71,72,73,74,75]. The MLEM algorithm exhibits an unfavorable property whereby noise and edge artifacts tend to increase as the iterations progress [76, 77]. Thus, practical solutions involve early stopping of iterations and/or post-smoothing using a Gaussian filter [78]. The MAP reconstruction presents an alternative solution that often achieves a more favorable balance between noise and contrast than the above-mentioned techniques [79]. The posterior probability of image \({\varvec{x}}\) given data \({\varvec{y}}\) is expressed through Bayes’ theorem as follows:
where \(P\left( {\varvec{x}} \right)\) is the prior probability of image \({\varvec{x}}\). The prior probability is assumed to be the following exponential function called the Gibbs distribution:
where \(Z\) is a partition function that makes the sum of the probabilities 1, and \(U\left( {\varvec{x}} \right)\) is an energy function designed to be small when the image is correct. The negative log-posterior likelihood is defined as follows:
where \(\beta\) is a hyperparameter that adjusts the influence of the prior distribution. Various MAP estimations are customized based on the selection of the prior distribution in the form of the Gibbs distribution. A commonly used energy function for the Gibbs distribution is as follows:
where \(V\left( \cdot \right)\) is a potential function, \(N_{j}\) is a set of neighboring voxels for the \(j\)-th voxel, and \({\omega }_{j{j}{\prime}}\) is a weight between neighboring voxels. The weight is typically defined as the inverse of the distance between neighboring voxels. Examples of potential functions include quadratic and relative difference [74], as follows:
where \(\gamma\) is a hyperparameter controlling the shape of relative difference. To minimize negative log-posterior likelihood function, Green’s one-step-late method [72] is commonly used as follows:
In the PET image reconstruction, the use of MAPEM with a quadratic prior provides a smoother image than the MLEM algorithm in low-count situations, as shown in Fig. 1.
With the emergence of PET/CT and PET/magnetic resonance imaging (MRI) scanners, the MAPEM algorithms that incorporate additional anatomical information from CT and MR images [80,81,82,83,84] were also developed. For example, we can incorporate MRI information into MAPEM by setting the weight \({\omega }_{j{j}{\prime}}\) based on the difference between \(j\)- and \({j}{\prime}\)-th voxel values of MRI (as detailed in Sect. 5). As shown in Fig. 1, MR-guided MAPEM can provide images with enhanced smoothness while preserving the organ boundaries.
Currently, the trajectory of PET image reconstruction is undergoing a deeper evolution, propelled by the integration of state-of-the-art deep learning technology in conjunction with computer vision techniques [85,86,87,88,89]. Figure 2 shows a classification of the deep learning methods for PET data in this review, which are strategically categorized into three distinct classes. First, the earliest deep learning methods for PET imaging primarily focused on post-processing for PET image denoising. Notably, these methods do not strictly perform image reconstruction processes. Second, a direct image reconstruction is a data-driven approach to learn a direct mapping from sinogram to PET image using training datasets of sinograms and reconstructed images. Third, an iterative reconstruction is a hybrid approach that utilizes existing image reconstruction combined with neural-network image enhancement. We proceed with more details of deep learning-based PET imaging methods in the following sections.

Overview of the deep learning methods for PET data: They are divided into three categories; post-processing (denoising), direct reconstruction, and iterative reconstruction methods using neural networks (NNs)
3 Deep learning for PET image denoising
Reconstructed PET images typically exhibit a low signal-to-noise ratio, owing to physical degradation factors and limited statistical counts. Low-dose radiotracers or short-time scans that reduce patient burden accelerate the degradation of PET images, potentially affecting diagnostic accuracy. This remains a major challenge and an effective restoration approach for low-quality PET images is essential. The restoration of PET images is sometimes included as a “reconstruction” process; however, this section focuses on restoration methods by post-processing after reconstruction, distinguishing it from reconstruction that generates images from measurement data.
Noise occurs as the image reconstruction is ill conditioned, such that a small perturbation of the measurement data greatly affects the image with much larger perturbations, as follows:
where \(\widehat{{\varvec{x}}}\), \({\varvec{x}}\), and \({\varvec{n}}\) are the degraded PET image, true PET image, and degraded component, respectively. The PET image denoising (or restoration) task is an inverse problem, whereby restoring the original image from a degraded image additively mixed with statistical noise complicated by the image reconstruction process. In recent years, deep learning approaches have been proposed to train the relationship between \(\widehat{{\varvec{x}}}\) and \({\varvec{x}}\) using the following minimization problem:
where \(f\) represents a neural-network model with trainable parameters \(\theta\), \(E\) is a loss function such as a mean-squared error (MSE) or mean absolute error. In general, deep learning-based PET image denoising aims to acquire data-driven nonlinear mapping from low-quality to high-quality PET images. It provides better denoising performance while retaining the spatial resolution and quantitative accuracy compared with classical denoising methods. In this section, we introduce deep learning-based PET image denoising methods based on the power of convolutional neural networks (CNNs) that specialize in image mappings in three ways to be covered below: supervised learning, self-supervised and unsupervised learning, and emerging approaches.
3.1 Supervised learning approach
Supervised learning is an approach used in machine learning to train models based on labeled data. PET image denoising tasks require huge datasets, comprising pairs of high- and low-quality PET images, as shown in Eq. (14). The evolution of deep learning has led to the transformation of shallow CNNs, initially implemented with only a few convolutional layers into architectures with deeper layers. This progress has enabled more potent PET image denoising capabilities, as evidenced by their superior performance [90]. Starting with these successes, CNN architectures have more complex features and have developed into structures specialized for image denoising and medical image processing, as shown in Fig. 3. Among them, the U-Net proposed by Ronneberger et al. [91] and 3D U-Net proposed by Çiçek [92] for semantic segmentation are widely used for PET image denoising [93,94,95]. A typical U-Net architecture consists of a contracting path to capture the context from the input image and a symmetric expanding path that up-samples the extracted feature map. In addition, the U-Net architecture introduces skip connections that pass the feature maps at each resolution of the contracting path to the expanding path. Residual learning [96] has also been proposed, in which the noise component contained in the image is output based on the idea that it is easier to leave only latent noise rather than retain the complex visual features of the PET image in the hidden layer [97,98,99,100]. Perceptual loss, which is based on high-level feature representations extracted from a pre-trained VGG16 on ImageNet, has been shown to improve the visual quality of PET images compared to general loss functions, such as the MSE [101]. Recently, the widespread use of PET/CT or PET/MR scanners has facilitated the simultaneous acquisition of functional and anatomical images. Therefore, PET image denoising is also performed by combining multimodal anatomical information, such as CT [102, 103] or MR images [104,105,106,107,108,109,110,111,112], thereby achieving superior denoising performance compared with PET alone.

© 2023 SNCSC. Reprinted with permission from Wang et al. [159]
Overview of the various deep learning architectures for PET image denoising. (a) U-Net model. (b) Multi-modal network using anatomical information. (c) GAN model. (d) Vision Transformer (ViT) model. (e) Swin Transformer image restoration network (SwinIR).
The advent of generative adversarial networks (GAN) has led to breakthroughs in the field of image generation [113]. The GAN consists of two competing neural networks: a generator and a discriminator. In addition to adopting a network, such as a U-Net, which is capable of image-to-image translation as a generator, it can be regarded as a training method that considers the adversarial loss based on the output from the discriminator. GAN training proceeds such that the label data are no longer distinguishable from the output images of the CNN, thereby synthesizing denoised PET images with less spatial blur and better visual quality [114,115,116]. Common models for denoising by GANs include Conditional GAN [117] and Pix2Pix [118], while incorporating various network structures [119, 120] and additional loss functions, such as least squares [121, 122], task-specific perceptual loss [123], pixelwise loss [124], and Wasserstein distance with a gradient penalty [125], have all been reported to improve denoising performance. CycleGAN is a method that consists of two generator and discriminator pairs with cycle consistency loss [126], which can train denoising tasks without a corresponding direct pairing between the degraded and original PET images, which is conventionally essential (Fig. 4) [127,128,129,130,131].

© 2019 IOP Publishing. Reprinted with permission from Lei et al. [127]
Examples of the denoised whole body.18F-FDG PET images by supervised learning approaches. Sample images showing (a) CT, (b) full-count PET, (c) low-count PET, and denoised PET images corresponding to the (d) U-Net, (e) GAN, and (f) CycleGAN. (g) Line profiles in sagittal section.
3.2 Self-supervised and unsupervised learning approaches
Collecting a large number of high-quality PET images for supervised learning is particularly difficult in clinical practice. Furthermore, the generalization performance for various PET tracers can be poor, and denoised images may have inherent biases affecting use with unknown data, such as disease, scanner, and noise levels, which are not included in the training data. To overcome these challenges, self-supervised and unsupervised learning approaches have attracted a steadily growing interest. Self-supervised learning generally refers to training algorithms that use self-labels automatically generated from unannotated data. Noise2Noise is a representative self-supervised denoising approach that restores clean images from multiple independent corrupt images [132] and is also reported to be effective for PET image denoising [133, 134]. To avoid the constraints of Noise2Noise, which requires more than one noise realization, Noise2Void, an unsupervised approach using a blind-spot network design [135], has also been used for PET image denoising [136].
Among the unsupervised learning approaches, the deep image prior (DIP), which uses a CNN structure as an intrinsic regularizer and does not require the preparation of a prior training dataset [137], has achieved better performance in PET image denoising [138,139,140]. DIP training is formulated as follows:
where \(\Vert \bullet \Vert\) is the L2 loss, \(f\) represents the CNN model with trainable parameters \(\theta\), the training label \({{\varvec{x}}}_{0}\) is the noisy PET image, and \({\varvec{z}}\) is the network input. After reaching an optimal stopping criterion, the CNN outputs the final denoised PET image, \({{\varvec{x}}}^{*}\). Conditional DIP (CDIP) [141, 142], which uses anatomical information instead of the original random noise as the network input, promotes denoising performance, and an attention mechanism to weight the multi-scale features extracted from the anatomical image guides the spatial details and semantic features of the image more effectively (Fig. 5) [143]. A four-dimensional DIP can perform end-to-end dynamic PET image denoising by introducing a feature extractor and several dozen reconstruction branches [144]. Recently, a pre-trained model using population information from a large number of existing datasets has been shown to improve DIP-based PET image denoising [145]. Furthermore, the self-supervised pre-training model acquired transferable and generalizable visual representations from only low-quality PET images; it achieves robust denoising performance for various PET tracers and scanner data [146].

© 2021 Elsevier. Reprinted with permission from Onishi et al. [143]
Examples of the denoised brain 18F-florbetapir PET images by unsupervised learning approaches. From left to right, the sample images showing the MR, standard-count PET, noisy PET, and denoised PET images corresponding to the Gaussian filter (GF), image-guided filter (IGF), DIP, MR-DIP (CDIP), and MR-guided deep decoder (GDD).
3.3 Emerging approaches
Currently, deep learning-based PET image restoration technology has already been implemented in commercial PET scanners [13, 14, 147] with Food and Drug Administration-cleared commercially available software [148,149,150,151,152], making significant contributions in clinical practice. Moreover, deep learning continues to develop rapidly, with emerging approaches and novel applications being frequently proposed.
The transformer architecture revolutionizes sequence tasks with self-attention and efficiently captures distant dependencies [153]. In particular, the Vision Transformer (ViT) [154] and Swin Transformer [155] effectively handle both local and global features, more so than CNNs. These transformer models have been adapted for PET image denoising and in some cases have reported to outperform CNN-based denoising performance (Fig. 6) [156,157,158,159,160,161]. The emergence of diffusion models resulted in a breakthrough in the field of image generation, following variational autoencoders and GANs. The effectiveness of denoising diffusion probabilistic models [162] for PET image denoising has also been investigated [163, 164]. From the viewpoint of personal information protection, federated learning, which enables decentralized learning without the need to export clinical data, is beginning to be applied to PET image denoising [165, 166]. In addition, uncertainty estimation [167, 168] and noise-aware networks [169,170,171] can provide additional value to conventional denoising methods. The advancement of PET state-of-the-art scanners, represented currently by total-body PET scanners [172], will pave the way for further applications of deep learning.

© 2023 SNCSC. Reprinted with permission from Wang et al. [159]
Examples of denoised 18F-FDG PET images by emerging approaches. Each column (a) to (d) indicates different patients or organs. From left to right, the sample images show the standard-count PET, low-count PET, and denoised PET images, corresponding to the enhanced deep super-resolution network (EDSR), EDSR-ViT, GAN, U-Net, and Swin Transformer image restoration network (SwinIR).
4 Deep learning for direct PET image reconstruction
Deep learning-based direct PET image reconstruction is a data-driven approach in which the reconstructed PET image, x, can be directly transformed from the measurement data, y, through a neural-network model, f, with trainable weights, \(\theta\). This is expressed as a problem of minimizing the following objective function:
where E is a loss function, such as the MSE. The direct reconstruction approach is completely different from previous approaches in that it attempts to find an image reconstruction mechanism entirely from the training dataset without involving physical models, such as forward or backprojection.
The earliest direct image reconstruction algorithm in the field of nuclear medicine was probably a single-photon emission CT (SPECT) image reconstruction algorithm using a perceptron with two hidden layers, as proposed by Floyd in 1991 [173], before the advent of deep learning. In this method, a four-layer perceptron was used, consisting of an input layer that considers the measurement sinogram as 1D data, one trainable hidden layer, another hidden layer with fixed weights for the backprojection calculation, and an output layer, as shown in Fig. 7. This pioneering work demonstrated that it was possible to realize a data-driven FBP method in which the first hidden layer works as a trainable kernel in the projection data space, and the second hidden layer works as a backprojection. The trained kernel in the projection data space delivers a kernel similar to that corresponding to a ramp filter in the frequency domain, as would be expected.

Schematic illustration of the earliest direct image reconstruction algorithm for SPECT by Floyd in 1991 [173]. The network realizes a data-driven FBP method in which the first hidden layer works as a trainable kernel in the projection data space, and the second hidden layer works as a backprojection. Note that the first hidden layer performed 1D filtering in the actual implementation using the common trainable weights at each angle
After 27 years, the advent of automated transform by manifold approximation (AUTOMAP) proposed by Zhou et al. in 2018 [174] led to the development of more modern direct image reconstruction algorithms using both fully connected (FC) layer as well as CNNs. The AUTOMAP architecture introduces dense (FC) connections in the first and second layers of the neural-network structure, as shown in Fig. 8. An interesting aspect of the dense connections in the AUTOMAP architecture is that they can work as an inverse transformation from measurement data to reconstructed MR and PET images in global operations using dense connections.

Schematic illustration of the AUTOMAP architecture by Zhou et al. in 2018 [174]. The network introduces dense connections in the first and second layers of the neural-network structure, which can work as an inverse transformation from measurement data to the reconstructed images in global operation
Inspired by the success of AUTOMAP, Häggström et al. proposed the DeepPET method for direct PET image reconstruction using an FCN architecture [175], as shown in Fig. 9. The DeepPET architecture consists of an encoder–decoder network that mimics some modifications of the VGG16 network [176], which has several improvements to address the challenges of using FCNs for direct image reconstruction. First, the encoder part initially utilizes larger convolution filter kernel sizes to perform a wider operation in the sinogram space, similar to the global operation with dense connections in the AUTOMAP architecture. Second, a deeper layered network structure allows the bottleneck features to obtain better latent representations. The size of the bottleneck feature is 18 × 17 × 1024, indicating that almost no spatial information of the input sinogram remains. The DeepPET has much fewer trainable parameters than the AUTOMAP, which uses dense connection layers (approximately 800 million trainable parameters for AUTOMAP compared to approximately 60 million for DeepPET [18]) and can train with a smaller dataset. DPIR-Net, a network structure similar to DeepPET, improves PET image quality by adding perceptual and adversarial losses to the loss function [177]. In addition, direct image reconstruction for long-axial field-of-view PET scanners has been developed [178]. DirectPET, which incorporates a Radon inversion layer that connects a masked region of the sinogram to a local patch of the image in the neural network as a PET physical model, has also been proposed [179, 180]. Furthermore, direct image reconstruction using modern network structures, such as a transformer network, and physics-informed networks have been developed [181, 182].

Schematic illustration of the DeepPET architecture by Häggström et al. in 2019 [175]. The arrows collectively represent the two convolution layers. The encoder part initially utilizes larger convolution filter kernel sizes of 7 × 7 in the red arrow and 5 × 5 in the blue arrows to work wider operation in the sinogram space, similar to the global operation with dense connections in the AUTOMAP architecture
These direct PET image reconstruction algorithms are expected to represent the next generation of fast and accurate image reconstruction methods; however, they have some limitations. We consider the DeepPET reconstruction results shown in Fig. 10 as an example. At a first glance, the direct reconstruction algorithms produce good PET images from sinograms. However, the detailed structures may differ from those obtained using the OSEM algorithm. This discrepancy may arise because obtaining an accurate inverse transformation from sinograms to reconstructed images using a data-driven approach is challenging. Consequently, these algorithms may generate artifacts or false structures in the reconstructed PET images. Another critical challenge is that the algorithms are limited to 2D image reconstruction, owing to graphics processing unit memory capacity. Therefore, these algorithms require a large number of training datasets to learn the backprojection task in a data-driven manner.

Another strategy for direct PET image reconstruction involves the use of TOF information. In general, acquired PET data (list-mode format data) are first histogrammed into the sinogram space. However, a different strategy directly creates histograms of the acquired PET data in the image space, known as the histo-image [183]. Whiteley et al. proposed the FastPET method, which obtains accurate PET images with a faster calculation time from the histo-image blurred by the TOF resolution in the LOR direction for each event (Fig. 11) [184]. The FastPET method differs from other direct image reconstruction methods, such as AUTOMAP and DeepPET, because the FastPET framework uses input images in the image space instead of the sinogram space. This implies that FastPET can employ CNNs, such as the U-Net structure. The advantage of this strategy is that it can be easily extended to 3D PET data because the sizes of the input data and network structure are quite small compared to those in other direct image reconstruction algorithms. Furthermore, some improved methods use the direction information of the acquired PET data by dividing the histo-image into several projection angles (Fig. 12) [185,186,187].

Schematic illustration of the FastPET framework for TOF-PET image reconstruction by Whiteley et al. in 2021 [184]

Results of FastPET reconstruction. Columns correspond to the phantom image, list-mode DRAMA, FastPET without and with direction information (from left to right). Reconstructed images were tagged using the mean and standard deviation of the contrast recovery coefficients (CRCs) of three tumor regions. The use of directional information (Ote and Hashimoto [186]) improves reconstruction performance (FastPET [184]). The figure is reprinted with a modification from the work of Ote and Hashimoto [186]
5 Deep learning for iterative PET image reconstruction
Deep learning-based iterative PET image reconstruction is a hybrid approach that combines existing iterative PET image reconstruction algorithms based on physical and statistical models with deep learning algorithms. There are two main approaches: one involves incorporating a neural network as an equality constraint, and the other involves integrating a neural network into the objective function as a penalty. The former approach to synthetic PET image reconstruction is represented by the following equation:
where L is the negative Poisson log-likelihood function and z is the input to the neural network, f, with trainable weights, \(\theta\). A simpler solution involves utilizing the pre-trained model f for the PET image denoising task and updating the reconstructed PET image.Footnote 1 This optimization problem is solved such that the measurement data align with the projection of the denoised PET image output from the neural network. In other words, the denoised PET images from the neural network were as consistent with the measurement data as possible, although they were the output of the neural-network denoising.
Gong et al. proposed an iterative PET image reconstruction algorithm using a synthesis-based prior [188]. The algorithm transforms the constrained optimization problem in Eq. (17) into an unconstrained optimization problem using the augmented Lagrangian format and is solved using the alternating direction method of multipliers (ADMM) algorithm [189]. The reconstructed results of the method by Gong et al. achieved superior performance in terms of lesion contrast and white matter noise tradeoff, as shown in Figs. 13 and 14, respectively. This framework can be reasonably extended by modifying the denoiser network. For example, Xie et al. replaced the network with a GAN generator incorporating a self-attention mechanism [190] to enhance the image quality without introducing blurring [191]. This method produced a better lesion contrast recovery and background noise tradeoff than the other methods. Alternatively, high-quality PET images can be obtained without any prior training dataset by introducing a DIP as a constraint, which uses the intrinsic prior of the CNN structure [192]. Ote et al. implemented 3D list-mode PET image reconstruction using DIP [193] by replacing the negative log-likelihood function in Eq. (17) with a list-mode log-likelihood function [194]. Additionally, some iterative reconstruction methods have also been proposed using only backpropagation without any backprojection process (Figs. 15 and 16) [195,196,197].

© 2019 IEEE. Reprinted with permission from Gong et al. [188]
Reconstructed results of the iterative PET image reconstruction algorithm using CNN representation [188]. Columns represent high count ground truth, EM reconstruction with the Gaussian filtering, fair penalty-based penalized reconstruction, dictionary learning-based reconstruction [198], CNN denoising, and the proposed iterative PET image reconstruction using CNN.

© 2019 IEEE. Reprinted with permission from Gong et al. [188]


© 2022 IEEE. Reprinted with permission from Hashimoto et al. [195]
Reconstructed results of the iterative PET image reconstruction using the DIP framework [195]. Columns represent MR image, ground truth, FBP, MLEM with Gaussian filtering, DIP reconstruction by Gong et al. [192], proposed methods with random noise and MRI input [195].The proposed method with MRI input is visually close to the ground truth.
Next, we considered the latter approach for iterative PET image reconstruction using an analysis-based prior as follows:
where R is an energy function, modulated the influence by the regularization parameter, β. For example, we consider a simpler case, where the energy function is as follows:
where j denotes the voxel index. Intuitively, Eq. (19) is less constraining than the synthetic PET image reconstruction because optimization is performed to ensure that the reconstructed PET image does not deviate far from the neural-network output in the image space [18], while not requiring equality with the output of the neural network.
Mehranian and Reader proposed PET image reconstruction via FBSEM-Net [199], which uses a forward–backward splitting algorithm [200]. The FBSEM-Net architecture is illustrated in Fig. 17. Using PET-MR data, FBSEM-Net can enhance PET image quality compared to other conventional reconstruction algorithms, as shown in Fig. 18. Kim et al. proposed a deep learning-based iterative PET image reconstruction [201] that introduced local linear fitting inspired by guided filtering [202] to the energy function for bias reduction in blind denoising, which is as follows:
where x is the PET image, f is the denoiser network with weights, \(\theta\), ⊙ is the Hadamard product, and q and b denote the local linear fitting coefficients. The method was divided into substeps for the denoiser network and local linear fitting using the ADMM algorithm. Gong et al. proposed MAPEM-Net, which can be easily implemented by incorporating a potential function into neural-network optimization [203]. In addition, various other iterative PET image reconstruction algorithms have been proposed for PET and SPECT [204,205,206,207,208,209,210,211,212,213,214,215,216].


6 Deep learning for dynamic PET image reconstruction
PET can be used to analyze the temporal pharmacokinetics of PET tracers through continuous measurements after the administration of radiopharmaceuticals. Usually, kinetic parameters, such as Ki, are estimated by fitting compartment models to the dynamic PET images of each voxel reconstructed over short-time frames. Alternatively, direct parametric reconstruction algorithms for dynamic PET data have been developed to enable accurate noise modeling [217,218,219].
With the advancement of deep learning, several dynamic PET image reconstruction methods using CNN have been proposed [220,221,222,223]. Li et al. expanded the DeepPET algorithm to direct the parametric image reconstruction from small-frame sinograms without using an input function [224]. Gong et al. introduced direct linear parametric PET image reconstruction using a nonlocal DIP architecture [225] with a linear kinetic model layer [226].
Dual-tracer PET imaging can measure two PET tracers in a single scan, which may be useful for diagnosing and tracking diseases as another application of dynamic PET [227, 228]. Deep learning has been reported to be useful for these approaches [229,230,231,232,233,234].
7 Conclusion and future perspectives
We conducted a comprehensive review of deep learning-based PET image denoising and reconstruction. Remarkable strides in deep learning-based PET image reconstruction are noteworthy. Recent advancements in PET scanner innovations are equally impressive and have aligned seamlessly with progress made in the field of deep learning technology. One of the recent breakthroughs in PET hardware is total-body PET geometry [235,236,237] that obtains high-sensitivity PET data and can provide extremely less noisy training datasets for deep learning-based PET image reconstruction [238]. Another noteworthy innovation is the TOF technology discussed in Sect. 4. Along with advancements in PET detectors [239,240,241,242], ultrafast TOF detectors of 30 ps have been developed, enabling reconstruction-free positron emission imaging [243]. This synergy between state-of-the-art TOF and deep learning technologies has pushed the limits of TOF performance [244,245,246]. Undoubtedly, the integration of deep learning will play a pivotal role in enhancing the performance of not only PET imaging but also signal processing [247,248,249,250].
Change history
16 March 2024
A Correction to this paper has been published: https://doi.org/10.1007/s12194-024-00794-x
Notes
The updated image for each iteration can be used for neural-network input z.
References
LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436–44.
Goodfellow IJ, Bengio Y, Courville A. Deep learning. Cambridge, MA, USA: MIT Press; 2016 http://www.deeplearningbook.org.
Schmidhuber J. Deep learning in neural networks: An overview. Neural Netw. 2015;61:85–117.
Suzuki K. Overview of deep learning in medical imaging. Radiol Phys Technol. 2017;10(3):257–73.
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, et al. A survey on deep learning in medical image analysis. Med Image Anal. 2017;42:60–88.
Shen D, Wu G, Suk H. Deep learning in medical image analysis. Annu Rev Biomed Eng. 2017;19:221–48.
Lee JG, Jun S, Cho YW, Lee H, Kim GB, et al. Deep learning in medical imaging: general overview. Korean J Radiol. 2017;18(4):570–84.
Fujita H. AI-based computer-aided diagnosis (AI-CAD): the latest review to read first. Radiol Phys Technol. 2020;13:6–19.
Kaji S, Kida S. Overview of image-to-image translation by use of deep neural networks: denoising, super-resolution, modality conversion, and reconstruction in medical imaging. Radiol Phys Technol. 2019;12(3):235–48.
Matsubara K, Ibaraki M, Nemoto M, Watabe H, Kimura Y. A review on AI in PET imaging. Ann Nucl Med. 2022;36(2):133–43.
PET with Advanced Intelligent Clear IQ-Engine | Nuclear Medicine | Canon Medical Systems. https://global.medical.canon/products/nuclear_medicine/PET-with-Advanced. Accessed 15 August 2023.
FUJIFILM Endoscopy. https://www.fujifilm-endoscopy.com/cadeye. Accessed 15 August 2023.
Wang T, Qiao W, Wang Y, Wang J, Lv Y, et al. Deep progressive learning achieves whole-body low-dose 18F-FDG PET imaging. EJNMMI Phys. 2022;9:82.
Mehranian A, Wollenweber SD, Walker MD, Bradley KM, Fielding PA, et al. Deep learning–based time-of-flight (ToF) image enhancement of non-ToF PET scans. Eur J Nucl Med Mol Imaging. 2022;49:3740–9.
Liu F, Jang H, Kijowski R, Bradshaw T, McMillan AB. Deep learning MR imaging–based attenuation correction for PET/MR imaging. Radiology. 2018;286(2):676–84.
Liu F, Jang H, Kijowski R, Zhao G, Bradshaw T, McMillan AB. A deep learning approach for 18F-FDG PET attenuation correction. EJNMMI Phys. 2018;5(1):1–15.
Gong K, Berg E, Cherry SR, Qi J. Machine learning in PET: from photon detection to quantitative image reconstruction. Proc IEEE. 2019;108(1):51–68.
Reader AJ, Corda G, Mehranian A, da Costa-Luis C, Ellis S, Schnabel JA. Deep learning for PET image reconstruction. IEEE Trans Radiat Plasma Med Sci. 2020;5(1):1–25.
Lee JS. A review of deep-learning-based approaches for attenuation correction in positron emission tomography. IEEE Trans Radiat Plasma Med Sci. 2020;5(2):160–84.
Hashimoto F, Ito M, Ote K, Isobe T, Okada H, Ouchi Y. Deep learning-based attenuation correction for brain PET with various radiotracers. Ann Nucl Med. 2021;35:691–701.
Gong K, Kim K, Cui J, Wu D, Li Q. The evolution of image reconstruction in PET: From filtered back-projection to artificial intelligence. PET Clin. 2021;16(4):533–42.
Liu J, Malekzadeh M, Mirian N, Song TA, Liu C, Dutta J. Artificial intelligence-based image enhancement in PET imaging: Noise reduction and resolution enhancement. PET Clin. 2021;16(4):553–76.
Reader AJ, Schramm G. Artificial Intelligence for PET Image Reconstruction. J Nucl Med. 2021;62:1330–3.
Reader AJ, Pan B. AI for PET image reconstruction. Br J Radiol. 2023. https://doi.org/10.1259/bjr.20230292.
Phelps ME. PET: molecular imaging and its biological applications. New York: Springer; 2012.
Schoder H, Gonen M. Screening for cancer with PET and PET/CT: potential and limitations. J Nucl Med. 2007;48(Suppl 1):4S-18S.
Minamimoto R, Senda M, Uno K, Jinnouchi S, Iinuma T, et al. Performance profile of FDG-PET and PET/CT for cancer screening on the basis of a Japanese Nationwide Survey. Ann Nucl Med. 2007;21:481–98.
Zhu L, Ploessl K, Kung HF. PET/SPECT imaging agents for neurodegenerative diseases. Chem Soc Rev. 2014;43(19):6683–91.
Barthel H, Schroeter ML, Hoffmann KT, Sabri O. PET/MR in dementia and other neurodegenerative diseases. Semin Nucl Med. 2015;45:224–33.
Jones T, Rabiner EA. The development, past achievements, and future directions of brain PET. J Cereb Blood Flow Metab. 2012;32:1426–54.
Onishi Y, Isobe T, Ito M, Hashimoto F, Omura T, Yoshikawa E. Performance evaluation of dedicated brain PET scanner with motion correction system. Ann Nucl Med. 2022;36:746–55.
National Research Council (2006) Health risks from exposure to low levels of ionizing radiation: BEIR VII phase 2. The National Academies Press, Washington, DC. https://doi.org/10.17226/11340
Ramachandran GN, Lakshminarayanan AV. Three-dimensional reconstruction from radiographs and electron micrographs: Application of convolutions instead of Fourier transforms. Proc Natl Acad Sci. 1971;68(9):2236–40.
Shepp LA, Logan BF. The Fourier reconstruction of a head section. IEEE Trans Nucl Sci. 1974;21(3):21–43.
Tanaka E, Iinuma T. Correction functions for optimizing the reconstructed image in transverse section scan. Phys Med Biol. 1975;20:789–98.
Defrise M, Kinahan PE. Data acquisition and image reconstruction for 3D PET in The Theory and Practice of 3D PET. Dordrecht: Springer; 1998.
Radon J. On the determination of functions from their integral values along certain manifolds. IEEE Trans Med Imaging. 1986;5(4):170–6.
Colsher JG. Fully three-dimensional positron emission tomography. Phys Med Biol. 1980;25:103–15.
Kinahan PE, Rogers JG. Analytic 3D image reconstruction using all detected events. IEEE Trans Nucl Sci. 1989;36:964–8.
Townsend DW, Spinks TJ, Jones T, Geissbühler A, Defrise M, et al. Three-dimensional reconstruction of PET data from a multi-ring camera. IEEE Trans Nucl Sci. 1989;36:1056–65.
Townsend DW, Geissbühler A, Defrise M, Hoffman EJ, Spinks TJ, et al. Fully three-dimensional reconstruction for a PET camera with retractable septa. IEEE Trans Med Imag. 1991;10:505–12.
Townsend DW, Bendriem B. Introduction to 3D PET. In: Bendriem B, Townsend DW, eds. The Theory and Practice of 3D PET. Dordrecht: Springer; 1998.
Grootoonk S, Spinks TJ, Michel C, Jones T, Correction for scatter using a dual energy window technique in a tomograph operated without septa. In,. IEEE Medical Imaging Conference Record. Nuclear Science Symposium and Medical Imaging Conference. 1991;1991:1569–73.
Bendriem B, Trébossen R, Frouin V, Scatter SAAPET, Acquisitions CUS, with Low and High Lower Energy Thresholds. In,. IEEE Medical Imaging Conference Record. Nuclear Science Symposium and Medical Imaging Conference. 1993;1993:1779–83.
Bailey DL, Meikle SR. A convolution-subtraction method for 3D PET. Phys Med Biol. 1994;39:411–24.
Ollinger JM. Model-Based Scatter Correction for Fully 3D PET. Phys Med Biol. 1996;41:153–76.
Watson CC, Newport D, Casey ME. A single scatter simulation technique for scatter correction in 3D PET. In: Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine. Dordrecht, The Netherlands: Kluwer Acad.; 1996. p. 255–268.
Thielemans K, Manjeshwar M, Tsoumpas C, Jansen FP. A new algorithm for scaling of PET scatter estimates using all coincidence events. In: 2007 IEEE IEEE Nuclear Science Symposium Conference Record, pp. 3586–3590, doi: https://doi.org/10.1109/NSSMIC.2007.4436900.
Watson CC, Casey ME, Michel C, Bendriem B. Advances in scatter correction for 3D PET/CT. IEEE Trans Radiat Plasma Med Sci. 2020;4:570–87.
Defrise M, Clackdoyle R, Townsend DW. Image reconstruction from truncated, two-dimensional, parallel projections. Inverse Probl. 1995;11:983–94.
Defrise M, Kinahan PE, Michel C, Rogers JG, Townsend DW, Clackdoyle R. Exact and approximate rebinning algorithms for 3-D PET data. IEEE Trans Med Imaging. 1997;11:145–58.
Kinahan PE, et al. Fast iterative image reconstruction of 3D PET data. In: 1996 IEEE Nuclear Science Symposium. Conference Record. Anaheim, CA, USA; 1996. p. 1918–22 vol.3. doi: https://doi.org/10.1109/NSSMIC.1996.588009.
Comtat C, Kinahan PE, Defrise M, Townsend DW, Michel C, et al. Simultaneous reconstruction of activity and attenuation in the presence of singles events. IEEE Trans Nucl Sci. 1998;45:1083–9.
Obi T, Matej S, Lewitt RM, Herman GT. 2.5D simultaneous multi-slice reconstruction by iterative algorithms from Fourier-rebinned PET data. IEEE Trans Med Imaging. 2000;19:474–484.
Shepp LA, Varidi Y. Maximum likelihood reconstruction for emission tomography. IEEE Trans Med Imaging. 1982;1(2):113–22.
Lange K, Carson R. EM reconstruction algorithm for emission and transmission tomography. J Comput Assist Tomogr. 1984;8(2):306–16.
Vardi Y, Shepp LA, Kaufuman L. A statistical model for positron emission tomography. J Amer Stat Assoc. 1985;80(389):8–20.
Qi J, Leahy RM. Iterative reconstruction techniques in emission computed tomography. Phys Med Biol. 2006;51(15):R541–78.
Hudson HM, Larkin RS. Accelerated image reconstruction using ordered subsets of projection data. IEEE Trans Med Imaging. 1994;13(4):601–9.
Browne J, de Pierro AB. A row-action alternative to the EM algorithm for maximizing likelihood in emission tomography. IEEE Trans Med Imaging. 1996;15(5):687–99.
Tanaka E, Kudo H. Subset-dependent relaxation in block-iterative algorithm for image reconstruction in emission tomography. Phys Med Biol. 2003;48(10):1405–22.
Murayama H, Yamaya T. Eiichi Tanaka, Ph.D. (1927–2021): pioneer of the gamma camera and PET in nuclear medicine physics. Radiol Phys Technol. 2023;16:1–7.
Qi J, Leahy RM, Cherry SR, Chatziioannou A, Farquhar TH. High-resolution 3D Bayesian image reconstruction using the microPET small-animal scanner. Phys Med Biol. 1998;43(4):1001–13.
Reader AJ, Ally S, Bakatselos F, Manavaki R, Walledge RJ, et al. One-pass list-mode EM algorithm for high-resolution 3-D PET image reconstruction into large arrays. IEEE Trans Nucl Sci. 2002;49(3):693–9.
Lee K, Kinahan PE, Fessler JA, Miyaoka RS, Janes M, Lewellen TK. Pragmatic fully 3D image reconstruction for the MiCES mouse imaging PET scanner. Phys Med Biol. 2004;49(19):4563–78.
Yamaya T, Hagiwara N, Obi T, Yamaguchi M, Ohyama N, et al. Transaxial system models for jPET-D4 image reconstruction. Phys Med Biol. 2005;50(22):5339–55.
Panin VY, Kehren F, Michel C, Casey M. Fully 3-D PET reconstruction with system matrix derived from point source measurements. IEEE Trans Med Imaging. 2006;25(7):907–21.
Matej S, Lewitt RM. Efficient 3D grids for image reconstruction using spherically-symmetric volume elements. IEEE Trans Nucl Sci. 1995;42(4):1361–70.
Reader AJ, Sureau FC, Comtat C, Trébossen R, Buvat I. Joint estimation of dynamic PET images and temporal basis functions using fully 4D ML-EM. Phys Med Biol. 2006;51(21):5455–74.
Levitan E, Herman GT. A maximum a posteriori probability expectation maximization algorithm for image reconstruction in emission tomography. IEEE Trans Med Imaging. 1987;6(3):185–92.
Herbert T, Leachy R. A generalized EM algorithm for 3-D Bayesian reconstruction from projection data using Gibbs priors. IEEE Trans Med Imaging. 1989;8(2):194–202.
Green PJ. Bayesian reconstructions from emission tomography data using a modified EM algorithm. IEEE Trans Med Imaging. 1990;9(1):84–92.
De Pierro AR, Yamagishi MEB. Fast EM-like methods for maximum “a posteriori” estimates in emission tomography. IEEE Trans Med Imaging. 2001;20(4):280–8.
Nuyts J, Beque D, Dupont P, Mortelmans L. A concave prior penalizing relative differences for maximum-a-posteriori reconstruction in emission tomography. IEEE Trans Nucl Sci. 2002;49(1):56–60.
Alenius S, Ruotsalainen U. Generalization of median root prior reconstruction. IEEE Trans Med Imaging. 2002;21(11):1413–20.
Snyder DL, Miller MI, Politte DG. Noise and edge artifacts in maximum-likelihood reconstructions for emission tomography. IEEE Trans Med Imaging. 1987;6(3):228–38.
Wilson DW, Tsui BMW, Barrett HH. Noise properties of the EM algorithm: II. Monte Carlo simulations Phys Med Biol. 1994;39(5):847–71.
Snyder DL, Miller MI. The use of sieves to stabilize images produced with the EM algorithm for emission tomography. IEEE Trans Nucl Sci. 1985;32(5):3864–72.
Ahn S, Ross SG, Asma E, Miao J, Jin X, et al. Quantitative comparison of OSEM and penalized likelihood image reconstruction using relative difference penalties for clinical PET. Phys Med Biol. 2015;60(15):5733–51.
Comtat C, Kinahan PE, Fessler JA, Beyer T, Townsend DW, et al. Clinically feasible reconstruction of 3D whole-body PET/CT data using blurred anatomical labels. Phys Med Biol. 2002;47:1–20.
Bowsher JE, Yuan H, Hedlund LW, Turkington TG, Akabani G, et al. Utilizing MRI information to estimate F18-FDG distributions in rat flank tumors. In: IEEE Nuclear Science Symposium and Medical Imaging Conference. 2004. pp. 2488–2492. doi: https://doi.org/10.1109/NSSMIC.2004.1462760.
Nuyts J. The use of mutual information and joint entropy for anatomical priors in emission tomography. In: IEEE Nuclear Science Symposium and Medical Imaging Conference. 2007. pp. 4149–4154. doi: https://doi.org/10.1109/NSSMIC.2007.4437034.
Mameuda Y, Kudo H. New anatomical-prior-based image reconstruction method for PET/SPECT. In: IEEE Nuclear Science Symposium and Medical Imaging Conference. 2007. pp. 4142–4148. doi: https://doi.org/10.1109/NSSMIC.2007.4437033.
Bai B, Li Q, Leahy RM. MR guided PET image reconstruction. Semin Nucl Med. 2013;43(1):30–44.
Buades A, Coll B, Morel J-M. A non-local algorithm for image denoising. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 2005;2 pp. 60–65. doi: https://doi.org/10.1109/CVPR.2005.38.
Aharon M, Elad M, Bruckstein A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans Signal Process. 2006;54(11):4311–22.
Wang G, Qi J. Penalized likelihood PET image reconstruction using patch-based edge-preserving regularization. IEEE Trans Med Imaging. 2012;31(12):2194–204.
Tang J, Yang B, Wang Y, Ying L. Sparsity-constrained PET image reconstruction with learned dictionary. Phys Med Biol. 2016;61(17):6347–68.
Dong J, Kudo H. Proposal of compressed sensing using nonlinear sparsifying transform for CT image reconstruction. Med Imag Tech. 2016;34:235–44.
Xiang L, Qiao Y, Nie D, An L, Lin W, et al. Deep Auto-context Convolutional Neural Networks for Standard-Dose PET Image Estimation from Low-Dose PET/MRI. Neurocomputing. 2017;267(6):406–16.
Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI 2015:234–241. doi: https://doi.org/10.1007/978-3-319-24574-4_28.
Çiçek Ö, Abdulkadir A, Lienkamp SS, Brox T, Ronneberger O. 3D U-Net: learning dense volumetric segmentation from sparse annotation. In: Ourselin S, Joskowicz L, Sabuncu MR, Unal G, Wells W, editors. Medical Image Computing and Computer Assisted Intervention (MICCAI) LNCS, vol. 9901. Cham: Springer; 2016. p. 424–32.
Sanaat A, Arabi H, Mainta I, Garibotto V, Zaidi H. Projection Space Implementation of Deep Learning-Guided Low-Dose Brain PET Imaging Improves Performance over Implementation in Image Space. J Nucl Med. 2020;61(9):1388–96.
Schaefferkoetter J, Yan J, Ortega C, Sertic A, Lechtman E, et al. Convolutional neural networks for improving image quality with noisy PET data. EJNMMI Res. 2020;10(1):105.
Liu H, Wu J, Lu W, Onofrey JA, Liu YH, Liu C. Noise reduction with cross-tracer and cross-protocol deep transfer learning for low-dose PET. Phys Med Biol. 2020;65(18): 185006.
Zhang K, Zuo W, Chen Y, Meng D, Zhang L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans Image Process. 2017;26(7):3142–55.
Liu CC, Huang HM. Partial-ring PET image restoration using a deep learning based method. Phys Med Biol. 2019;64: 225014.
Spuhler K, Serrano-Sosa M, Cattell R, DeLorenzo C, Huang C. Full-count PET recovery from low-count image using a dilated convolutional neural network. Med Phys. 2020;47(10):4928–38.
Sano A, Nishio T, Masuda T, Karasawa K. Denoising PET images for proton therapy using a residual U-net. Biomed Phys Eng Express. 2021;7: 025014.
Mehranian A, Wollenweber SD, Walker MD, Bradley KM, Fielding PA, et al. Image enhancement of whole-body oncology [18F]-FDG PET scans using deep neural networks to reduce noise. Eur J Nucl Med Mol Imaging. 2022;49(2):539–49.
Gong K, Guan J, Liu CC, Qi J. PET Image Denoising Using a Deep Neural Network Through Fine Tuning. IEEE Trans Radiat Plasma Med Sci. 2019;3(2):153–61.
Ladefoged CN, Hasbak P, Hornnes C, Højgaard L, Andersen FL. Low-dose PET image noise reduction using deep learning: application to cardiac viability FDG imaging in patients with ischemic heart disease. Phys Med Biol. 2021;66: 054003.
Xie Z, Li T, Zhang X, Qi W, Asma E, Qi J. Anatomically aided PET image reconstruction using deep neural networks. Med Phys. 2021;48(9):5244–58.
Chen KT, Gong E, de Carvalho Macruz FB, Xu J, Boumis A, et al. Ultra-Low-Dose 18F-Florbetaben Amyloid PET Imaging Using Deep Learning with Multi-Contrast MRI Inputs. Radiology. 2019;290(3):649–56.
Liu CC, Qi J. Higher SNR PET image prediction using a deep learning model and MRI image. Phys Med Biol. 2019;64(11): 115004.
Wang YR, Baratto L, Hawk KE, Theruvath AJ, Pribnow A, et al. Artificial intelligence enables whole-body positron emission tomography scans with minimal radiation exposure. Eur J Nucl Med Mol Imaging. 2021;48(9):2771–81.
Schramm G, Rigie D, Vahle T, Rezaei A, Van Laere K, et al. Approximating anatomically-guided PET reconstruction in image space using a convolutional neural network. Neuroimage. 2021;224(1): 117399.
He Y, Cao S, Zhang H, Sun H, Wang F, et al. Dynamic PET Image Denoising With Deep Learning-Based Joint Filtering. IEEE Access. 2021;9:41998–2012.
da Costa-Luis CO, Reader AJ. Micro-Networks for Robust MR-Guided Low Count PET Imaging. IEEE Trans Radiat Plasma Med Sci. 2021;5(2):202–12.
Chen KT, Schürer M, Ouyang J, Koran MEI, Davidzon G, et al. Generalization of deep learning models for ultra-low-count amyloid PET/MRI using transfer learning. Eur J Nucl Med Mol Imaging. 2020;47(13):2998–3007.
Chen KT, Toueg TN, Koran MEI, Davidzon G, Zeineh M, et al. True ultra-low-dose amyloid PET/MRI enhanced with deep learning for clinical interpretation. Eur J Nucl Med Mol Imaging. 2021;48(8):2416–25.
Sun H, Jiang Y, Yuan J, Wang H, Liang D, et al. High-quality PET image synthesis from ultra-low-dose PET/MRI using bi-task deep learning. Quant Imaging Med Surg. 2022;12(12):5326–42.
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, et al. Generative Adversarial Nets. In: Advances in neural information processing systems, vol. 27. 2014.
Wang Y, Yu B, Wang L, Zu C, Lalush DS, et al. 3D conditional generative adversarial networks for high-quality PET image estimation at low dose. Neuroimage. 2018;174(1):550–62.
Xue S, Guo R, Bohn KP, Matzke J, Viscione M, et al. A cross-scanner and cross-tracer deep learning method for the recovery of standard-dose imaging quality from low-dose PET. Eur J Nucl Med Mol Imaging. 2022;49(6):1843–56.
Hu Y, Lv D, Jian S, Lang L, Cui C, et al. Comparative study of the quantitative accuracy of oncological PET imaging based on deep learning methods. Quant Imaging Med Surg. 2023;13(6):3760–75.
Mirza M, Osindero S. Conditional Generative Adversarial Nets. arXiv preprint arXiv:1411.1784. 2014.
Isola P, Zhu JY, Zhou T, Efros AA. Image-to-Image Translation with Conditional Adversarial Networks. arXiv preprint arXiv:1611.07004. 2018.
Wang Y, Zhou L, Yu B, Wang L, Zu C, et al. 3D auto-context-based locality adaptive multi-modality GANs for PET synthesis. IEEE Trans Med Imaging. 2019;38(6):1328–39.
Fu Y, Dong S, Niu M, Xue L, Guo H, et al. AIGAN: Attention-encoding Integrated Generative Adversarial Network for the reconstruction of low-dose CT and low-dose PET images. Med Image Anal. 2023;86: 102787.
Lu W, Onofrey JA, Lu Y, Shi L, Ma T, et al. An investigation of quantitative accuracy for deep learning based denoising in oncological PET. Phys Med Biol. 2019;64(16): 165019.
Xue H, Teng Y, Tie C, Wan Q, Wu J, et al. A 3D attention residual encoder–decoder least-square GAN for low-count PET denoising. Nucl Instrum Methods Phys Res A. 2020;983(11): 164638.
Ouyang J, Chen KT, Gong E, Pauly J, Zaharchuk G. Ultra-low-dose PET reconstruction using generative adversarial network with feature matching and task-specific perceptual loss. Med Phys. 2019;46(8):3555–64.
Jeong YJ, Park HS, Jeong JE, Yoon HJ, Jeon K, et al. Restoration of amyloid PET images obtained with short-time data using a generative adversarial networks framework. Sci Rep. 2021;11:4825.
Gong Y, Shan H, Teng Y, Tu N, Li M, et al. Parameter-Transferred Wasserstein Generative Adversarial Network (PT-WGAN) for Low-Dose PET Image Denoising. IEEE Trans Radiat Plasma Med Sci. 2021;5(2):213–23.
Zhu JY, Park T, Isola P, Efros AA. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv preprint arXiv:1703.10593. 2017.
Lei Y, Dong X, Wang T, Higgins K, Liu T, et al. Whole-body PET estimation from low count statistics using cycle-consistent generative adversarial networks. Phys Med Biol. 2019;64(21): 215017.
Zhou L, Schaefferkoetter JD, Tham IW, Huang G, Yan J. Supervised learning with cyclegan for low-dose FDG PET image denoising. Med Image Anal. 2020;65: 101770.
Zhao K, Zhou L, Gao S, Wang X, Wang Y, et al. Study of low-dose PET image recovery using supervised learning with CycleGAN. PLoS ONE. 2020;15(9): e0238455.
Sanaat A, Shiri I, Arabi H, Mainta I, Nkoulou R, Zaidi H. Deep learning-assisted ultra-fast/low-dose whole-body PET/CT imaging. Eur J Nucl Med Mol Imaging. 2021;48(8):2405–15.
Ghafari A, Sheikhzadeh P, Seyyedi N, Abbasi M, Farzenefar S, et al. Generation of 18F-FDG PET standard scan images from short scans using cycle-consistent generative adversarial network. Phys Med Biol. 2022;67: 215005.
Lehtinen J, Munkberg J, Hasselgren J, Laine S, Karras T, et al. Noise2Noise: Learning Image Restoration without Clean Data. arXiv preprint arXiv:1803.04189. 2018.
Yie SY, Kang SK, Hwang D, Lee JS. Self-supervised PET Denoising. Nucl Med Mol Imaging. 2020;54(6):299–304.
Kang SK, Yie SY, Lee JS. Noise2Noise Improved by Trainable Wavelet Coefficients for PET Denoising. Electronics. 2021;10(13):1529.
Krull A, Buchholz TO, Jug F. Noise2Void-Learning Denoising from Single Noisy Images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019; pp. 2129–2137. doi: https://doi.org/10.1109/CVPR.2019.00223.
Song TA, Yang F, Dutta J. Noise2Void: unsupervised denoising of PET images. Phys Med Biol. 2021;66: 214002.
Ulyanov D, Vedaldi A, Lempitsky V. Deep image prior. Int J Comput Vis. 2020;128:1867–88.
Hashimoto F, Ohba H, Ote K, Teramoto A, Tsukada H. Dynamic PET Image Denoising Using Deep Convolutional Neural Networks Without Prior Training Datasets. IEEE Access. 2019;7:96594–603.
Sun H, Peng L, Zhang H, He Y, Cao S, Lu L. Dynamic PET Image Denoising Using Deep Image Prior Combined With Regularization by Denoising. IEEE Access. 2021;9:52378–92.
Yang CH, Huang HM. Simultaneous Denoising of Dynamic PET Images Based on Deep Image Prior. J Digit Imaging. 2022;35(4):834–45.
Cui J, Gong K, Guo N, Wu C, Meng X, et al. PET image denoising using unsupervised deep learning. Eur J Nucl Med Mol Imaging. 2019;46(13):2780–9.
Hashimoto F, Ohba H, Ote K, Teramoto A. Unsupervised dynamic PET image denoising with anatomical information. Med Imaging Inf Sci. 2020;37(3):58–61. https://doi.org/10.11318/mii.37.58.
Onishi Y, Hashimoto F, Ote K, Ohba H, Ota R, et al. Anatomical-guided attention enhances unsupervised PET image denoising performance. Med Image Anal. 2021;74: 102226.
Hashimoto F, Ohba H, Ote K, Kakimoto A, Tsukada H, Ouchi Y. 4D deep image prior: dynamic PET image denoising using an unsupervised four-dimensional branch convolutional neural network. Phys Med Biol. 2021;66: 015006.
Cui J, Gong K, Guo N, Wu C, Kim K, et al. Populational and individual information based PET image denoising using conditional unsupervised learning. Phys Med Biol. 2021;66: 155001.
Onishi Y, Hashimoto F, Ote K, Matsubara K, Ibaraki M. Self-Supervised Pre-Training for Deep Image Prior-Based Robust PET Image Denoising. IEEE Trans Radiat Plasma Med Sci. 2023. https://doi.org/10.1109/TRPMS.2023.3280907.
Tsuchiya J, Yokoyama K, Yamagiwa K, Watanabe R, Kimura K, et al. Deep learning-based image quality improvement of 18F-fluorodeoxyglucose positron emission tomography: a retrospective observational study. EJNMMI Phys. 2021;8(1):31.
Chaudhari AS, Mittra E, Davidzon GA, Gulaka P, Gandhi H, et al. Low-count whole-body PET with deep learning in a multicenter and externally validated study. NPJ Digit Med. 2021;4(1):127.
Katsari K, Penna D, Arena V, Polverari G, Ianniello A, et al. Artificial intelligence for reduced dose 18F-FDG PET examinations: a real-world deployment through a standardized framework and business case assessment. EJNMMI Phys. 2021;8(1):25.
Weyts K, Lasnon C, Ciappuccini R, Lequesne J, Corroyer-Dulmont A, et al. Artificial intelligence-based PET denoising could allow a two-fold reduction in [18F]FDG PET acquisition time in digital PET/CT. Eur J Nucl Med Mol Imaging. 2022;49(11):3750–60.
Weyts K, Quak E, Licaj I, Ciappuccini R, Lasnon C, et al. Deep Learning Denoising Improves and Homogenizes Patient [18F]FDG PET Image Quality in Digital PET/CT. Diagnosis. 2023;13(9):1626.
Margail C, Merlin C, Billoux T, Wallaert M, Otman H, et al. Imaging quality of an artificial intelligence denoising algorithm: validation in 68Ga PSMA-11 PET for patients with biochemical recurrence of prostate cancer. EJNMMI Res. 2023;13(1):50.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, et al. Attention Is All You Need. arXiv preprint arXiv:1706.03762. 2017.
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. 2020.
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv preprint arXiv:2103.14030. 2021.
Luo Y, Wang Y, Zu C, Zhan B, Wu X, et al. 3D Transformer-GAN for High-Quality PET Reconstruction. In: Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI) 2021: 24th International Conference, Strasbourg, France, 2021, Part VI; 2021. pp. 276–285. doi: https://doi.org/10.1007/978-3-030-87231-1_27.
Zhang L, Xiao Z, Zhou C, Yuan J, He Q, et al. Spatial adaptive and transformer fusion network (STFNet) for low-count PET blind denoising with MRI. Med Phys. 2022;49(1):343–56.
Jang SI, Pan T, Li Y, Heidari P, Chen J, et al. Spach Transformer: Spatial and Channel-wise Transformer Based on Local and Global Self-attentions for PET Image Denoising. IEEE Trans Med Imaging. 2023. https://doi.org/10.1109/TMI.2023.3336237.
Wang YR, Wang P, Adams LC, Sheybani ND, Qu L, et al. Low-count whole-body PET/MRI restoration: an evaluation of dose reduction spectrum and five state-of-the-art artificial intelligence models. Eur J Nucl Med Mol Imaging. 2023;50(5):1337–50.
Wang YR, Qu L, Sheybani ND, Luo X, Wang J, et al. AI Transformers for Radiation Dose Reduction in Serial Whole-Body PET Scans. Radiol Artif Intell. 2023;5(3): e220246.
Kruzhilov I, Kudin S, Vetoshkin L, Sokolova E, Kokh V. Whole-body PET image denoising for reduced acquisition time. arXiv preprint arXiv:2303.16085. 2023.
Ho J, Jain A, Abbeel P. Denoising Diffusion Probabilistic Models. arXiv preprint arXiv:2006.11239. 2020.
Gong K, Johnson KA, Fakhri GE, Li Q, Pan T. PET image denoising based on denoising diffusion probabilistic models. Eur J Nucl Med Mol Imaging. 2023. https://doi.org/10.1007/s00259-023-06417-8.
Han Z, Wang Y, Zhou L, Wang P, Yan B, et al. Contrastive Diffusion Model with Auxiliary Guidance for Coarse-to-Fine PET Reconstruction. arXiv preprint arXiv:2308.10157. 2023.
Zhou B, Miao T, Mirian N, Chen X, Xie H, et al. Federated Transfer Learning for Low-Dose PET Denoising: A Pilot Study With Simulated Heterogeneous Data. IEEE Trans Radiat Plasma Med Sci. 2023;7(3):284–95.
Zhou B, Xie H, Liu Q, Chen X, Guo X, et al. FedFTN: Personalized Federated Learning with Deep Feature Transformation Network for Multi-institutional Low-count PET Denoising. arXiv preprint arXiv:2304.00570. 2023.
Sudarshan VP, Upadhyay U, Egan GF, Chen Z, Awate SP. Towards lower-dose PET using physics-based uncertainty-aware multimodal learning with robustness to out-of-distribution data. Med Image Anal. 2021;73: 102187.
Cui J, Xie Y, Joshi AA, Gong K, Kim K, et al. PET Denoising and Uncertainty Estimation Based on NVAE Model Using Quantile Regression Loss. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer Nature Switzerland; 2022. doi: https://doi.org/10.1007/978-3-031-16440-8_17
Li Y, Cui J, Chen J, Zeng G, Wollenweber S, et al. A Noise-level-aware Framework for PET Image Denoising. arXiv preprint arXiv:2203.08034. 2022.
Sanaei B, Faghihi R, Arabi H. Employing Multiple Low-Dose PET Images (at Different Dose Levels) as Prior Knowledge to Predict Standard-Dose PET Images. J Digit Imaging. 2023;36(4):1588–96.
Xie H, Liu Q, Zhou B, Chen X, Guo X, Wang H, Li B, Rominger A, Shi K, Liu C. Unified Noise-Aware Network for Low-Count PET Denoising With Varying Count Levels. IEEE Trans Radiat Plasma Med Sci. 2023. https://doi.org/10.1109/TRPMS.2023.3334105.
Zhang J, Cui Z, Jiang C, Guo S, Gao F, Shen D. Hierarchical Organ-Aware Total-Body Standard-Dose PET Reconstruction From Low-Dose PET and CT Images. IEEE Trans Neural Netw Learn Syst. 2023. https://doi.org/10.1109/TNNLS.2023.3266551.
Floyd CE. An artificial neural network for SPECT image reconstruction. IEEE Trans Med Imaging. 1991;10:485–7.
Zhu B, Liu JZ, Cauley SF, Rosen BR, Rosen MS. Image reconstruction by domain-transform manifold learning. Nature. 2018;555:487–92.
Häggström I, Schmidtlein CR, Campanella G, Fuchs TJ. DeepPET: A deep encoder–decoder network for directly solving the PET image reconstruction inverse problem. Med Image Anal. 2019;54:253–62.
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
Hu Z, Xue H, Zhang Q, Gao J, Zhang N, et al. DPIR-Net: Direct PET image reconstruction based on the Wasserstein generative adversarial network. IEEE Trans Radiat Plasma Med Sci. 2020;5:35–43.
Ma R, Hu J, Sari H, Xue S, Mingels C, et al. An encoder-decoder network for direct image reconstruction on sinograms of a long axial field of view PET. Eur J Nucl Med Mol Imaging. 2022;49:4464–77.
Whiteley W, Luk WK, Gregor J. DirectPET: full-size neural network PET reconstruction from sinogram data. J Med Imaging. 2020;7: 032503.
Liu Z, Ye H, Liu H. Deep-learning-based framework for PET image reconstruction from sinogram domain. Appl Sci. 2022;12:8118.
Cui J, Zeng P, Zeng X, Wang P, Wu X, et al. TriDo-Former: A Triple-Domain Transformer for Direct PET Reconstruction from Low-Dose Sinograms. arXiv preprint arXiv:2308.05365.
Hashimoto F, Ote K. ReconU-Net: a direct PET image reconstruction using U-Net architecture with back projection-induced skip connection. arXiv preprint arXiv:2312.02494. 2023.
Matej S, Surti S, Jayanthi S, Daube-Witherspoon ME, Lewitt RM, Karp JS. Efficient 3-D TOF PET reconstruction using view-grouped histo-images: DIRECT—Direct image reconstruction for TOF. IEEE Trans Med Imaging. 2009;28(5):739–51.
Whiteley W, Panin V, Zhou C, Cabello J, Bharkhada D, Gregor J. FastPET: near real-time reconstruction of PET histo-image data using a neural network. IEEE Trans Radiat Plasma Med Sci. 2021;5:65–77.
Feng T, Yao S, Xi C, Zhao Y, Wang R, et al. Deep learning-based image reconstruction for TOF PET with DIRECT data partitioning format. Phys Med Biol. 2021;66: 165007.
Ote K, Hashimoto F. Deep-learning-based fast TOF-PET image reconstruction using direction information. Radiol Phys Technol. 2022;15:72–82.
Lv L, Zeng GL, Zan Y, Hong X, Guo M, et al. A back-projection-and-filtering-like (BPF-like) reconstruction method with the deep learning filtration from listmode data in TOF-PET. Med Phys. 2022;49(4):2531–44.
Gong K, Guan J, Kim K, Zhang X, Yang J, et al. Iterative PET image reconstruction using convolutional neural network representation. IEEE Trans Med Imaging. 2019;38:675–85.
Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found Trends Mach Learn. 2011;3:1–122.
Zhang H, Goodfellow I, Metaxas D, Odena A. Self-Attention Generative Adversarial Networks. In: Proceedings of the 36th International Conference on Machine Learning, Proceedings of Machine Learning Research. 2019;97:7354–7363.
Xie Z, Baikejiang R, Li T, Zhang X, Gong K, et al. Generative adversarial network based regularized image reconstruction for PET. Phys Med Biol. 2020;65(12): 125016.
Gong K, Catana C, Qi J, Li Q. PET image reconstruction using deep image prior. IEEE Trans Med Imaging. 2019;38:1655–65.
Ote K, Hashimoto F, Onishi Y, Isobe T, Ouchi Y. List-mode PET image reconstruction using deep image prior. IEEE Trans Med Imaging. 2023;42:1822–34.
Cao X, Xie Q, Xiao P. A regularized relaxed ordered subset list-mode reconstruction algorithm and its preliminary application to under-sampling PET imaging. Phys Med Biol. 2015;60(1):49–66.
Hashimoto F, Ote K, Onishi Y. PET image reconstruction incorporating deep image prior and a forward projection model. IEEE Trans Radiat Plasma Med Sci. 2022;6:841–6.
Hashimoto F, Onishi Y, Ote K, Tashima H, Yamaya T. Fully 3D implementation of the end-to-end deep image prior-based PET image reconstruction using block iterative algorithm. Phys Med Biol. 2023;68(15): 155009.
Shan Q, Wang J, Liu D. Deep Image Prior Based PET Reconstruction From Partial Data. IEEE Trans Radiat Plasma Med Sci. 2023. https://doi.org/10.1109/TRPMS.2023.3280674.
Chen S, Liu H, Shi P, Chen Y. Sparse representation and dictionary learning penalized image reconstruction for positron emission tomography. Phys Med Biol. 2015;60(2):807.
Mehranian A, Reader AJ. Model-based deep learning PET image reconstruction using forward–backward splitting expectation–maximization. IEEE Trans Radiat Plasma Med Sci. 2021;5:54–64.
Combettes PL, Pesquet JC. Proximal splitting methods in signal processing. In: Bauschke HH, Burachik RS, Combettes PL, Elser V, Luke DR, Wolkowicz H, editors. Fixed-Point Algorithms for Inverse Problems in Science and Engineering. New York, NY, USA: Springer; 2011. p. 185–212. doi: https://doi.org/10.1007/978-1-4419-9569-8_10.
Kim K, Wu D, Gong K, Dutta J, Kim JH, et al. Penalized PET reconstruction using deep learning prior and local linear fitting. IEEE Trans Med Imaging. 2018;37(6):1478–87.
He K, Sun J, Tang X. Guided image filtering. IEEE Trans Pattern Anal Mach Intell. 2013;35(6):1397–409.
Gong K, Wu D, Kim K, Yang J, Sun T, et al. MAPEM-Net: An unrolled neural network for Fully 3D PET image reconstruction. In: The 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine, Philadelphia, United States, 1107200, 2019. doi: https://doi.org/10.1117/12.2534904.
Gong K, Wu D, Kim K, Yang J, El Fakhri G, et al. EMnet: an unrolled deep neural network for PET image reconstruction. In: SPIE Medical Imaging 2019: Physics of Medical Imaging, San Diego, California, United States, 1094853, 2019. doi: https://doi.org/10.1117/12.2513096.
Lim H, Chun IY, Dewaraja YK, Fessler JA. Improved low-count quantitative PET reconstruction with an iterative neural network. IEEE Trans Med Imaging. 2020;39:3512–22.
Xie N, Gong K, Guo N, Qin Z, Wu Z, et al. Penalized-likelihood PET image reconstruction using 3D structural convolutional sparse coding. IEEE Trans Biomed Eng. 2022;69:4–14.
Hu R, Liu H. TransEM: Residual swin-transformer based regularized PET image reconstruction. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer Nature Switzerland; 2022. p. 184–193. doi: https://doi.org/10.1007/978-3-031-16440-8_18
Xie H, Thorn S, Liu YH, Lee S, Liu Z, et al. Deep-Learning-Based Few-Angle Cardiac SPECT Reconstruction Using Transformer. IEEE Trans Radiat Plasma Med Sci. 2022;7(1):33–40.
Li Z, Dewaraja YK, Fessler JA. Training End-to-End Unrolled Iterative Neural Networks for SPECT Image Reconstruction. IEEE Trans Radiat Plasma Med Sci. 2023;7(4):410–20.
Hu R, Chen Y, Kim K, Rockenbach MABC, Li Q, Liu H. DULDA: Dual-domain Unsupervised Learned Descent Algorithm for PET image reconstruction. arXiv preprint arXiv:2303.04661. 2023.
Reader AJ. Self-Supervised and Supervised Deep Learning for PET Image Reconstruction. arXiv preprint arXiv:2302.13086. 2023.
Liao S, Mo Z, Zeng M, Wu J, Gu Y, et al. Fast and low-dose medical imaging generation empowered by hybrid deep-learning and iterative reconstruction. Cell Rep Med. 2023;4(7): 101119.
Zhang Q, Hu Y, Zhao Y, Cheng J, Fan W, et al. Deep Generalized Learning Model for PET Image Reconstruction. IEEE Trans Med Imaging. 2023. https://doi.org/10.1109/TMI.2023.3293836.
Shen C, Xia W, Ye H, Hou M, Chen H, et al. Unsupervised Bayesian PET Reconstruction. IEEE Trans Radiat Plasma Med Sci. 2022;7(2):175–90.
Lv Y, Xi C. PET image reconstruction with deep progressive learning. Phys Med Biol. 2021;66(10): 105016.
Li J, Xi C, Dai H, Wang J, Lv Y, et al. Enhanced PET imaging using progressive conditional deep image prior. Phys Med Biol. 2023;68: 175047.
Kamasak ME, Bouman CA, Morris ED, Sauer K. Direct reconstruction of kinetic parameter images from dynamic PET data. IEEE Trans Med Imaging. 2005;24(5):636–50.
Matthews J, Bailey D, Price P, Cunningham V. The direct calculation of parametric images from dynamic PET data using maximum-likelihood iterative reconstruction. Phys Med Biol. 1997;42(6):1155–73.
Wang G, Qi J. Direct Estimation of Kinetic Parametric Images for Dynamic PET. Theranostics. 2013;3(10):802–15.
Yokota T, Kawai K, Sakata M, Kimura Y, Hontani H. Dynamic PET image reconstruction using nonnegative matrix factorization incorporated with deep image prior. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 3126–3135, 2019. doi: https://doi.org/10.1109/ICCV.2019.00322.
Wang B, Liu H. FBP-Net for direct reconstruction of dynamic PET images. Phys Med Biol. 2020;65: 235008.
Li S, Wang G. Deep kernel representation for image reconstruction in PET. IEEE Trans Med Imaging. 2022;41(11):3029–38.
Hu R, Cui J, Yu C, Chen Y, Liu H. STPDnet: Spatial-temporal convolutional primal dual network for dynamic PET image reconstruction. arXiv preprint arXiv:2303.04667, 2023.
Li Y, Hu J, Sari H, Xue S, Ma R, Kandarpa S, et al. A deep neural network for parametric image reconstruction on a large axial field-of-view PET. Eur J Nucl Med Mol Imaging. 2023;50(3):701–14.
Wang X, Girshick R, Gupta A, He K. Non-local neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018:7794–7803.
Gong K, Catana C, Qi J, Li Q. Direct reconstruction of linear parametric images from dynamic PET using nonlocal deep image prior. IEEE Trans Med Imaging. 2021;41(3):680–9.
Huang SC, Carson RE, Hoffman EJ, Kuhl DE, Phelps ME. An investigation of a double-tracer technique for positron computerized tomography. J Nucl Med. 1982;23(9):816–22.
Cheng X, Li Z, Liu Z, Navab N, Huang S-C, Keller U, Ziegler SI, Shi K. Direct parametric image reconstruction in reduced parameter space for rapid multi-tracer PET imaging. IEEE Trans Med Imaging. 2015;34(7):1498–512.
Xu J, Liu H. Deep-learning-based separation of a mixture of dual-tracer single-acquisition PET signals with equal half-lives: a simulation study. IEEE Trans Radiat Plasma Med Sci. 2019;3(6):649–59.
Xu J, Liu H. Three-dimensional convolutional neural networks for simultaneous dual-tracer PET imaging. Phys Med Biol. 2019;64(18): 185016.
Qing M, Wan Y, Huang W, Xu Y, Liu H. Separation of dual-tracer PET signals using a deep stacking network. Nucl Instrum Methods Phys Res A. 2021;1013: 165681.
Tong J, Wang C, Liu H. Temporal information-guided dynamic dual-tracer PET signal separation network. Med Phys. 2022;49(7):4585–98.
Zeng F, Fang J, Muhashi A, Liu H. Direct reconstruction for simultaneous dual-tracer PET imaging based on multi-task learning. EJNMMI res. 2023;13(1):7.
Pan B, Marsden PK, Reader AJ. Dual-Tracer PET Image Separation by Deep Learning: A Simulation Study. Appl Sci. 2023;13(7):4089.
Cherry SR, Jones T, Karp JS, Qi J, Moses WW, Badawi RD. Total-body PET: maximizing sensitivity to create new opportunities for clinical research and patient care. J Nucl Med. 2018;59(1):3–12.
Badawi RD, Shi H, Hu P, Chen S, Xu T, Price PM, et al. First human imaging studies with the EXPLORER total-body PET scanner. J Nucl Med. 2019;60(3):299–303.
Wang Y, Li E, Cherry SR, Wang G. Total-body PET kinetic modeling and potential opportunities using deep learning. PET clinics. 2021;16(4):613–25.
Ultra-low Dose PET Imaging Challenge - Grand Challenge. https://ultra-low-dose-pet.grand-challenge.org/. Accessed 22 August 2023.
Ota R. Photon counting detectors and their applications ranging from particle physics experiments to environmental radiation monitoring and medical imaging. Radiol Phys Technol. 2021;14:134–48.
Lecoq P, Morel C, Prior JO, Visvikis D, Gundacker S, et al. Roadmap toward the 10 ps time-of-flight PET challenge. Phys Med Biol. 2020;65(21):21RM01.
Ota R, Nakajima K, Ogawa I, Tamagawa Y, Shimoi H, et al. Coincidence time resolution of 30 ps FWHM using a pair of Cherenkov-radiator-integrated MCP-PMTs. Phys Med Biol. 2019;64(7):07LT01.
Ota R, Nakajima K, Ogawa I, Tamagawa Y, Kwon SI, et al. Lead-free MCP to improve coincidence time resolution and reduce MCP direct interactions. Phys Med Biol. 2021;66(6): 064006.
Kwon SI, Ota R, Berg E, Hashimoto F, Nakajima K, et al. Ultrafast timing enables reconstruction-free positron emission imaging. Nat Photonics. 2021;15(12):914–8.
Berg E, Cherry SR. Using convolutional neural networks to estimate time-of-flight from PET detector waveforms. Phys Med Biol. 2018;63(2):02LT01.
Onishi Y, Hashimoto F, Ote K, Ota R. Unbiased TOF estimation using leading-edge discriminator and convolutional neural network trained by single-source-position waveforms. Phys Med Biol. 2022;67(4):04NT01.
Maebe J, Vandenberghe S. Simulation study on 3D convolutional neural networks for time-of-flight prediction in monolithic PET detectors using digitized waveforms. Phys Med Biol. 2022;67(12): 125016.
Hashimoto F, Ote K, Ota R, Hasegawa T. A feasibility study on 3D interaction position estimation using deep neural network in Cherenkov-based detector: A Monte Carlo simulation study. Biomed Phys Eng Express. 2019;5(3): 035001.
Ote K, Ota R, Hashimoto F, Hasegawa T. Direct annihilation position classification based on deep learning using paired Cherenkov detectors: a Monte Carlo study. Appl Sci. 2020;10(22):7957.
He W, Zhao Y, Zhao X, Huang W, Zhang L, et al. A CNN-based four-layer DOI encoding detector using LYSO and BGO scintillators for small animal PET imaging. Phys Med Biol. 2023;68(9): 095021.
Lee S, Lee JS. Experimental evaluation of convolutional neural network-based inter-crystal scattering recovery for high-resolution PET detectors. Phys Med Biol. 2023;68(9): 095017.
Funding
Japan Society for Promotion of Science,JP22K07762,Fumio Hashimoto,Nakatani Foundation for Advancement of Measuring Technologies in Biomedical Engineering
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
This work was partially supported by the JSPS KAKENHI (grant number: JP22K07762) and the Nakatani Foundation.
Ethics approval
This article does not report any studies performed with human participants. This article does not report any studies performed with animals.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised to correct the equations 5 and 13.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Hashimoto, F., Onishi, Y., Ote, K. et al. Deep learning-based PET image denoising and reconstruction: a review. Radiol Phys Technol 17, 24–46 (2024). https://doi.org/10.1007/s12194-024-00780-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12194-024-00780-3