
Abstract
In this study, we recruited 50 chronic pain (neuropathic and nociceptive) and 43 pain-free controls to identify specific blood biomarkers of chronic neuropathic pain (CNP). Affymetrix microarray was carried out on a subset of samples selected 10 CNP and 10 pain-free control participants. The most significant genes were cross-validated using the entire dataset by quantitative real-time PCR (qRT-PCR). In comparative analysis of controls and CNP patients, WLS (P = 4.80 × 10–7), CHPT1 (P = 7.74 × 10–7) and CASP5 (P = 2.30 × 10–5) were highly significant, whilst FGFBP2 (P = 0.00162), STAT1 (P = 0.00223), FCRL6 (P = 0.00335), MYC (P = 0.00335), XCL2 (P = 0.0144) and GZMA (P = 0.0168) were significant in all CNP patients. A three-arm comparative analysis was also carried out with control as the reference group and CNP samples differentiated into two groups of high and low S-LANSS score using a cut-off of 12. STAT1, XCL2 and GZMA were not significant but KIR3DL2 (P = 0.00838), SH2D1B (P = 0.00295) and CXCR31 (P = 0.0136) were significant in CNP high S-LANSS group (S-LANSS score > 12), along with WLS (P = 8.40 × 10–5), CHPT1 (P = 7.89 × 10–4), CASP5 (P = 0.00393), FGFBP2 (P = 8.70 × 10–4) and FCRL6 (P = 0.00199), suggesting involvement of immune pathways in CNP mechanisms. None of the genes was significant in CNP samples with low (< 12) S-LANSS score. The area under the receiver operating characteristic (AUROC) analysis showed that combination of MYC, STAT1, TLR4, CASP5 and WLS gene expression could be potentially used as a biomarker signature of CNP (AUROC − 0.852, (0.773, 0.931 95% CI)).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Chronic neuropathic pain (CNP) is a debilitating condition caused by lesion or disease of the peripheral and central divisions of the somatosensory system (Colloca et al., 2017; van Hecke et al., 2014). Drug management of CNP provides symptomatic relief in some but not all patients and is associated with hazardous side effects (Colloca et al., 2017; Hoffman et al., 2017). This is largely due to the lack of objective biomarkers to guide diagnosis and choice of treatment (Backryd, 2015). The mechanism of CNP is also complicated by multiple and obscure pain aetiologies and involvement of many molecular and cellular pathways contributing to the perception of pain (Campbell & Meyer, 2006). It is suggested that different clinical pain manifestations and prognosis may be due to different mechanisms of CNP (Campbell & Meyer, 2006). To help improve pain management, there is a need to develop translational tools, such as well-validated quantitative biomarkers as indicators of disease phenotype and drug response.
A plethora of inflammatory molecules dominate the gene expression (transcriptome) profile of patient blood in CNP (Backryd, 2015). Various inflammatory molecules are associated with gender (Lopes et al., 2017; Sorge et al., 2011), Leeds Assessment of Neuropathic Symptoms and Signs (S-LANSS) scores (Bennett et al., 2005) and other clinical presentations (Lasselin et al., 2016; Sommer et al., 2018). Many non-inflammatory proteins have also been suggested to act as molecular mediators of CNP and are attracting interest for drug discovery and development of more selective analgesic drugs (Sommer et al., 2018). Examples of proteins that have been tested as potential biomarkers for pain include neurotrophic factors (Boucher & McMahon, 2001; Kelleher et al., 2017), cytokines (Ellis & Bennett, 2013; Uceyler & Sommer, 2012), neuropeptides (Carniglia et al., 2017), endothelin (Hans et al., 2008), heat shock proteins (Hutchinson et al., 2009; Lei et al., 2017; Zou et al., 2012), and GTP-cyclohydrolase 1 (GCH1) (Latremoliere & Costigan, 2011; Tegeder et al., 2006), although this list is not exhaustive. Studies utilising genetic tools such as genome-wide association studies (GWAS), transcriptome analysis with quantitative real-time PCR (qRT-PCR), protein expression studies and animal models along with other techniques have vastly contributed to the understanding of the molecular biological mechanisms contributing to CNP. Nevertheless, there is a need for comprehensive studies to contextualise how signalling pathways and different molecules synchronise in CNP. Gene expression studies coupled with newly developed statistical and bioinformatics tools can be useful for acquiring information about the molecular regulation of transcriptional responses of the peripheral nervous system to traumatic nerve injury.
Recently, we carried out a DNA microarray of 10 patients with chronic lower back pain and 10 pain-free controls to identify differentially expressed genes (Buckley et al., 2018). These genes were cross-validated using qRT-PCR of samples of dorsal horn tissue of rats having undergone spinal nerve ligation (SNL) or sham (placebo) surgery (Buckley et al., 2018). In this work, we have carried out Affymetrix microarray and qRT-PCR to differentiate the gene expression profiles of pain-free control and CNP patients. It is noteworthy that most of the studies in pain biomarker and drug-target discovery had been carried out in rat models and cross-species validation could be a major challenge due to fundamental metabolic differences between rats and humans (Buckley et al., 2018; Denk et al., 2016; Hutchinson et al., 2009; Latremoliere & Costigan, 2018; Lopes et al., 2017; Xue et al., 2014). Our study is more powerful than previous studies because it is based on clinical samples and presents a more realistic and accurate outlook of the transcriptional changes associated with pain in humans.
Materials and Methods
Sample Acquisition
Samples for this study were collected at the University of Huddersfield (control subjects) and through the Pain Management Services at Seacroft Hospital, Leeds, UK. A total of 50 CNP patients and 43 pain-free healthy controls participated in the study (Supplemental Tables 1 and 2). The pain patients were recruited based on the CNP (> 3 months) as their clinical diagnosis. According to the 7-item Leeds Assessment of Neuropathic Symptoms and Signs Pain Scale (S-LANSS) questionnaire, pain with S-LANSS score ≥ 12 is considered as neuropathic pain (Bennett et al., 2005). However, some CNP participants recruited in this study had SLANSS score < 12 although the clinical diagnosis was the pain of neuropathic origin. We consider these pain patients as CNP participants with nociceptive components as well. Both the controls and pain patients were excluded for any current diagnosis of diabetes, cancer, osteoarthritis, fibromyalgia and other complex metabolic diseases which could significantly alter their gene profiles. Controls did not have any symptoms of pain.
We performed sample size calculations based on gene expression analyses of a previous study of 10 disease individuals and 10 non-disease controls. We included gene expression data generated both by microarray and by qPCR. Independent calculations based on four significant transcripts resulted in corresponding sample size requirements of 21, 16, 27 and 15 participants per group to be able to reject the null hypothesis that the population means of the diseased and control groups were equal with probability (power) 0.8. The Type I error probability associated with this test of this null hypothesis is 0.05. Conservatively the required sample size for the current investigation was taken as being the largest of these figures; i.e. 27 per group or 54 in total. Other non-selected genes, with correspondingly larger effects, would lead to lower requirements, whereas those genes with lower effects would in turn require larger numbers in the study, and hence we conservatively aimed to analyse 35 participants per group (70 in total). Allowing for 20% attrition loss, we aimed to recruit a total of 86 individuals to the current 2-arm study (43 per group). As CNP is often associated with co-morbidities, our main focus in patient recruitment was to use a relatively homogenous population without any comorbidity to identify changes associated with CNP. A similar strategy for patient recruitment was used in a previous study on transcriptomic analysis of lower back pain patients (Dorsey et al., 2019).
Data for age, gender, Patient Health Questionnaire (PHQ-9) and State-Trait Anxiety Inventory (STAI) questionnaires, STAI-I and STAI-II for current and trait anxiety, respectively, were collected for all the participants (See Supplementary file for details). Clinical data related to pain including pain duration in months, self-reported pain, Leeds Assessment of Neuropathic Symptoms and Signs (S-LANSS), Chronic Pain Grade (CPG) and current medications were also recorded for CNP participants. The medication histories of patients were collected at the time of sample acquisition. Current medications were categorised as follows: (a) anti-inflammatory drugs, which included nonsteroidal anti-inflammatory drugs (NSAIDS), (b) antidepressants such as tricyclic antidepressants (TCAs), norepinephrine-serotonergic reuptake inhibitors (NSRIs) and selective serotonin reuptake inhibitors (SSRIs), (c) anticonvulsants and (d) opioid analgesics.
Venous blood samples were collected from the antecubital fossa of all participants using standard phlebotomy technique. Blood for RNA isolation was collected in 2.5 mL PAXgene Blood RNA tubes (BD Diagnostics, Wokingham, Berkshire, United Kingdom), which were stored at − 20 °C for < 24 h before transfer to − 80 °C for long-term storage.
Transcriptomic Analysis
A total of 10 samples from CNP (with a S-LANSS score > 12) and control groups (n = 20) were included for transcriptomic analysis. For transcriptomics, RNA was extracted using the PAXgene Blood RNA Kit (PreAnalytiX GmbH, Switzerland) as per the manufacturer’s instructions. Total RNA was labelled using an Ambion WT Expression kit (Life Technologies, Bleiswijk, Netherlands). The gene expression profiling was carried out using the GeneChip Human Transcriptome Array (HTA) 2.0 (Affymetrix, Santa Clara, CA, USA). The Affymetrix HTA 2.0 covered about 67,500 transcript clusters (genes), both coding and non-coding included. The labelling, hybridization, scanning and data extraction of microarray were performed by AROS Applied Biotechnology (Aarhus, Denmark) according to the recommended Affymetrix protocols. The digital signals obtained as CEL files were then processed using Affymetrix expression console (v1.4.1.46) with the standard configuration for expression arrays, including robust multi-array average (RMA) background correction (Irizarry et al., 2003), median polish probe-level signal summarization and quantile normalisation. The detectable genes were defined as significant detection signals [P-value (P) < 0.05] for more than 50% of probe sets in at least one of all samples. The normalised files were then followed by pairwise comparison analysis for obtaining differential gene expression between pain and control participants in Transcription analysis console v-4.0. Annotated transcripts, P < 0.05 (ANOVA) were considered suitable for further analysis.
Bioinformatics Analysis
Mapping of pathways, networks and biological functions of differentially expressed genes was carried out using Ingenuity Pathway Analysis (IPA) (Qiagen, Redwood City, CA, USA). P < 0.05 was used as a cut-off and 1069 annotated genes were analysed (494 downregulated and 575 upregulated) (Supplemental Table 3). Core analysis was carried out and both direct and indirect relationships were considered to generate the gene networks (Kramer et al., 2014). When generating networks, we used the settings of a maximum of 140 genes per network and 10 networks per analysis, as the higher number of genes allows for the possibility that the same network can include all focus genes. The molecules or pathways specific to humans, experimentally observed and predicted with high confidence were used in IPA to analyse gene expression data in the context of known biological response and regulatory networks. IPA returns P-values (P) for the networks and regulators based on Fisher’s exact test, which is a measure of the probability that the association between a set of focus genes in the experiment and a given process or pathway is due to random chance alone (Kramer et al., 2014). Activation z-score was used to predict directionality based on the underlying findings, relationship bias and dataset bias (Kramer et al., 2014). The transcription factors with maximum interconnected genes in IPA were further analysed by qRT-PCR. IPA and String version 10.5 (Szklarczyk et al., 2017) were used to generate the figures showing gene networks.
Quantitative PCR (qRT-PCR)
The qRT-PCR of selected genes was carried out for all participants. A total of 300 ng of RNA from each human sample was reverse transcribed using the Verso cDNA Synthesis Kit (Thermo Scientific™, UK) according to the manufacturer’s instructions. The complementary DNA was subsequently diluted tenfold. Amplification was performed in triplicate with a Roche LightCycler® 480 II (Roche Diagnostics Ltd., Burgess Hill, West Sussex, United Kingdom). Each 10 μl reaction mixture contained 3 μl of iTaq™ Universal SYBR® Green Supermix (Bio-Rad Laboratories, Berkeley, CA, USA), 300 nM of each forward and reverse primer (Supplemental Table 4) and 1 μl of diluted cDNA. Amplification protocol was as follows: Polymerase activation and DNA denaturation at 95 °C for 2 min, 40 cycles of denaturation at 95 °C for 5 s with annealing and extension at 60 °C for 30 s followed by fluorescence detection. Upon completion of thermal cycling, melt-curve analysis was carried out to confirm reaction specificity. The relative gene expression of the markers was normalised to the geometric mean of GAPDH and SDHA (Supplemental Table 4) and then to the control group, according to the 2–ΔΔCt method (Livak & Schmittgen, 2001). The levels of expression for each gene are presented as fold-changes in comparison to controls.
Statistical Analysis
Statistical analyses were carried out using in IBM SPSS Statistics version 26 taking into account qRT-PCR-based normalised gene expression, age and gender of the patients/control, the number of months patients have experienced pain, S-LANSS score, PHQ-9 score, CPG and ongoing medications of the patients. Medication data were recorded as binary variables, with intake of one or more individual medications within each medication group corresponding to a positive response. Primary outcome data were represented by gene expression levels, recorded on 23 genes of interest (See “Results” section for further details). Secondary outcome data were represented by the PHQ-9 scores, which was considered as both a potential predictor and outcome measure, due to uncertainties about its position on the causal pathway.
The sample was summarised descriptively.
The extent and nature of missing data were examined. Very small proportions of missing data were recorded. Little’s test revealed no evidence that this data was not missing completely at random (MCAR) (P = 0.207).
The P-values obtained from the ANCOVAs associated with the grouping variable were ordered and ranked. The Benjamini–Hochberg (B–H) critical value associated with each test was calculated, with the critical value for the ith P-value given by the expression \(Q\left( {i/m} \right)\), where m is the number of genes to be tested (23 in all analyses) and Q is the false discovery rate (FDR); set at 5% for all analyses. Any gene for which the P-value was lower than the corresponding B–H critical value was deemed to be significant (and highlighted in tabulated data); as were all genes above it in the ordered list (i.e. those with lower P-values). Significance was also determined using familywise error rate (FWER) control via the Bonferroni method (using a critical significance level of 0.217%); and using uncorrected P-values, to assess the sensitivity of the gene selection to the method used.
A series of univariate main effects analyses of covariance (ANCOVAs) were conducted on the data. The P-values obtained from the ANCOVAs associated with the grouping variable were ordered and ranked. The false discovery rate (FDR) was set at 5% for all analyses. Expression levels for each gene were considered in turn as the outcome. The PHQ-9 depression score was also considered as a secondary outcome. Goodness-of-fit of the models was assessed from the range of adjusted-R2 statistics obtained.
We carried out three series of univariate main effects ANCOVAs on the data:
-
1.
The first series of analyses included all CNP pain and control participants. Predictor variables included in these analyses were participant type (CNP or control), with age and gender included as controlling variables.
-
2.
In the second series of analyses a distinction was made between 50 CNP patients based on the S-LANSS score. Hence the predictor variables included in these analyses were patient type; CNP with SLANSS score ≥ 12, CNP with SLANSS score < 12, control (considered to represent the reference category). Age and gender were additionally included as controlling variables.
-
3.
A further series of univariate main effects ANCOVAs were conducted on the data arising from CNP patients only. In these analyses, the grouping variable was data available for pain patients only including CPG, months of pain experienced and medication in addition to gender and age. To avoid model overfitting, a sequential modelling strategy was utilised to eliminate predictor variables of no substantive importance. Predictor variables were assigned to blocks. The first block comprised the patient-reported PHQ-9 and CPG scores, plus the number of months for which the patient had experienced pain. The second block comprised the variables related to patient medications. The third block included age, gender and the grouping variable. In each of the lower blocks, patterns of significance amongst considered variables were examined, and any exhibiting greater levels of significance than expected were carried forward for inclusion as higher-priority variables in the next block.
The significant genes were grouped together for calculation of the area under the receiver operator characteristic (AUROC) curve both for the control versus CNP group comparison, and the high versus low S-LANSS group comparison. Following standard procedures, the ROC Curves were derived from predicted probabilities of a logistic regression analysis using the grouping variable as the state variable.
Ethical Approval
The blood samples used in this study were obtained with informed consent from the patients. All the methods were performed in compliance with the institutional protocols. This study was approved by the Yorkshire & The Humber – Bradford Leeds Research Ethics Committee (14/YH/0117) and adapted to the NIHR Clinical Research Network (Portfolio ID: 16774).
Results
Descriptive and Exploratory Analysis of the Participants
The characteristics of study participants are presented in Table 1 and Supplemental Tables 1 and 2. Amongst the 50 CNP participants, 36 patients had SLANSS score ≥ 12 whilst the remaining 14 patients had SLANSS score < 12 (Supplemental Table 2).
The pain group comprised 23 men (46.0%) and 27 women (54.0%); with a mean age of 46.5 years (SD 12.5 years). The control group comprised 15 men (34.9%) and 28 women (65.1%); with a mean age of 38.4 years (SD 14.8 years). One missing value was recorded on each of the PHQ-9 score and CPG. Missing values were not imputed.
In the CNP group, 24 patients (48.0%) took analgesics (non-steroidal anti-inflammatory drugs); 25 patients (50.0%) took antidepressants with significant analgesic properties; 22 patients (44.0%) took anticonvulsants; 33 patients (66.0%) took opioid analgesics. 48 out of 50 patients took medication from at least one group; with 4 patients taking medications from all 4 groups. The median number of groups from which medication taken was 2.
Within the pain group, the mean S-LANSS score was 15.3 (SD 7.96; range 0–24). The mean PHQ-9 score was 13.2 (SD 7.34; range 0–26); the median CPG was IV (range I-IV). The mean PHQ-9 score in controls was 2.21 (SD 2.34; range 0–8). Four patients (8.2%) had a chronic pain grade (CPG) of I; 8 patients (16.3%) had a CPG of II; 10 patients (20.4%) had a CPG of III; 27 patients (55.1%) had a CPG of IV.
Considering the 50 patients in the CNP group, 36 (72.0%) had SLANSS score ≥ 12 whilst 14 (28.0%) had SLANSS score < 12. The CNP patients with SLANSS score ≥ 12 comprised 15 men (41.7%) and 21 women (58.3%); with a mean age of 43.9 years (SD 11.4 years). The CNP patients with SLANSS score < 12 comprised 8 men (57.18%) and 6 women (42.9%); with a mean age of 53.1 years (SD 13.1 years).
In the CNP group patients with SLANSS score ≥ 12, 17 patients (47.2%) took analgesics (non-steroidal anti-inflammatory drugs); 18 patients (50%) took antidepressants with significant analgesic properties; 19 patients (52.7%) took anticonvulsants; 23 patients (63.8%) took opioid analgesics. 33 out of 36 patients took medication from at least one group; with 5 patients taking medications from all 4 groups.
Amongst the CNP group with SLANSS score < 12, 7 patients (50%) took analgesics (non-steroidal anti-inflammatory drugs); 3 patients (21.4%) took antidepressants with significant analgesic properties; 5 patients (35.7%) took anticonvulsants; 8 patients (57.14%) took opioid analgesics. 12 out of 14 patients took medication from at least one group; no patients took medications from all 4 groups.
Transcriptomic Analysis
All the arrays (10 CNP and 10 controls) passed the quality control tests carried out using Affymetrix console. The differential gene expression analysis of CNP vs control revealed the fold-change, P-value (P) and FDR-corrected P-value of the gene. None of the genes in the microarray could pass the criteria of FDR < 0.1. The principal component analysis (PCA) revealed that CNP and control groups were not clearly segregated across the first two PCAs (Supplemental Fig. 1). Therefore, we refrained from deriving any strict quantitative conclusions based on the microarray data and also cross-validated the top upregulated and downregulated genes using qRT-PCR. The top significant genes (P < 0.05) are presented in Table 2 and normalised gene expression as estimated by qRT-PCR is shown in Figs. 1 and 2.

∆Ct is inversely related to the gene expression. In the box red line shows the mean and pink and blue area indicates values within 95% confidence interval and standard deviation 1, respectively. The markers indicate the normalised ∆Ct values of the genes in the samples. The names of statistically significant genes are outlined in a box and their P-values are marked with asterisks within the figure; ***P < 0.001
Validation of top upregulated genes observed in the Affymetrix analysis of CNP vs control samples in larger subset by qRT-PCR.

∆Ct is inversely related to the gene expression. In the box red line shows the mean and pink and blue area indicates values within 95% confidence interval and standard deviation 1, respectively. The markers indicate the normalised ∆Ct values of genes in the samples. The names of statistically significant genes are outlined in a box and their P-values are marked with asterisks within the figure; **P < 0.01 and *P < 0.05
Validation of top downregulated genes observed in the Affymetrix analysis of CNP vs control samples in larger subset by qRT-PCR.
IPA core analysis was carried out on annotated differentially expressed genes obtained from microarray analysis using a cut-off of P < 0.05 (Supplemental Table 3). The core analysis associated the dataset with several canonical pathways each of which correlated with a P-value as described in the “Methods” section. A low P-value implies over-representation of focus genes in the pathway. We used the P < 1 × 10−4 as a cut-off which revealed the seven most significant pathways (Fig. 3). The inflammasome pathway (z-score = 2.236) and Th1 pathway (z-score = − 2.233) showed the highest and lowest z-score, respectively (Supplemental Figs. 2–4). The positive and negative z-score implied the predicted activation and inactivation of pathway, respectively. It also calculated a ratio of the number of genes from the list included in the canonical pathway and the total number of genes that make up the canonical pathway. The inflammasome pathway ranked the highest with a ratio of 0.25 (Fig. 3).

The ratio of the number of genes from the dataset that map to the pathway divided by the total number of genes that map to the respective pathway is indicated on the right-side y-axis
Canonical pathways in IPA analysis which are most significant to the dataset using a P-value 1 × 10–4 as the cut-off.
The IPA core analysis also provided the most significant diseases and disorders that could be linked to the dataset across all the genes (Table 3). The top disease identified, with 222 molecules, was in general related to the inflammatory response which further reflects the role of inflammatory genes in pain phenotype. The smaller P-values imply that the association is non-random.
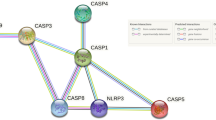
We limited our further IPA analysis to ten network functions (Table 4). All the generated networks were interconnected by one or more genes. The most significant network was associated with biological functions of developmental disorders, hereditary disorders and neurological diseases and included 123 focus molecules (Table 4). We merged the top five generated networks to obtain a master network of 687 focus molecules. The molecules with more than thirty-five interconnections are presented in Fig. 4 and these could be important in pain manifestations since it has been hypothesised that highly connected molecules are most likely associated with diseases or biological functions (Barabasi et al., 2011; Jeong et al., 2000). This also included Glycogen synthase kinase 3 beta (GSK3B) which had more than 50 connections in the generated master network.

A master network generated by merging top five networks identified the above nodes with maximum connectivity (> 35 connections). The nodes that were upregulated and downregulated in the dataset are coloured red and blue, respectively. The nodes that have been predicted by IPA and were not present in the input dataset for microarray are filled in grey. The solid and dashed lines show direct and indirect connections, respectively. The circle around the node itself indicates self-regulation. The legend to the node shapes is presented in Supplemental Fig. 3
Highly connected nodes in IPA based on the Affymetrix microarray data.
Key Transcription Factors in CNP Networks
The IPA analysis predicted various upstream regulators based on the differential gene dataset. We filtered the upstream regulators using transcription regulator as molecule type and z-score >|2| to predict key transcription regulators. Also, as the target molecules of many upstream regulators show an overlap, we merged the regulatory networks to display as one network. These included STAT3, HDAC5, JUNB, CBX5, IRF7, HDAC6, NFE2L2, HDAC2, IKZF1, GATA1, NFκBIA, RUNX3, SREBF1, TBX21, RELB, MTPN and MYC (Fig. 5). The transcription factors STAT3, NFκBIA and MYC showed more than 25 interconnections. NFκB pathway has been long associated with inflammation (Lawrence, 2009; Tak & Firestein, 2001), a hallmark of CNP (Hartung et al., 2015; Shih et al., 2015) so we did not analyse it any further. The transcription factors STAT3 and MYC were analysed by qRT-PCR for cross-validation. We also carried out the qRT-PCR of STAT1 as it has been suggested to play a role in CNP (Denk et al., 2016). Also, STAT1 directly regulates T-box 21 (TBX21) which is one of the top regulatory molecules predicted by IPA based on our dataset.

The transcription factors connected to more than 25 nodes are highlighted in yellow. The figure was generated in the program STRING. The coloured lines between the transcription factors are related to source of the database/relation between the genes; cyan: Curated databases, magenta: experimentally determined, blue: gene co-occurrence, black: co-expression, light blue: protein homology and light green: text mining
Merged networks of transcription regulators with z-score >|2.0| in IPA.
We also carried out pathway analysis of our microarray dataset by the in-built WikiPathways (Slenter et al., 2018) function in Transcription analysis console v-4.0. The PI3-Akt pathway was the top pathway by count linked to the dataset (Supplemental Fig. 5). PI3-Akt pathway includes both GSK3B and MYC which have been suggested as the important nodes in the IPA analysis (Supplemental Fig. 5).
qRT-PCR-Based Validation of Differentially Expressed Genes (CNP vs Control)
We carried out the qRT-PCR of the eighteen most frequent upregulated and downregulated genes observed in the microarray. A direct comparison of fold-change between the two methods (microarray and qRT-PCR) was not possible (Dallas et al., 2005; Morey et al., 2006), although some broad conclusions could be derived. Table 2 shows that the directionality of differential gene expression was nearly the same in the two methods for all of the upregulated and downregulated genes. The qRT-PCR-based normalised gene expression of these genes in CNP and control samples is presented in Figs. 1 and 2. We also estimated the age- and gender-controlled p-values of qRT-PCR data between CNP and control participants and an FDR of 5% was applied to filter the significant genes (Supplemental Table 5). Genes with a P < 0.05 were considered significant in the qRT-PCR analysis. Amongst the upregulated genes, choline phosphotransferase 1 (CHPT1) gene was highly significant in both the microarray (P = 0.0086) and qRT-PCR (P = 7.74 × 10–7, respectively). Wntless Wnt ligand secretion mediator (WLS) was significant in the microarray (P = 0.038) whilst it was found to be strongly significant in qRT-PCR (P = 4.80 × 10–7). Amongst the downregulated genes, chemokine (C motif) ligand 2 gene (XCL2) was highly significant in the microarray (P = 0.0005) but showed less significance in qRT-PCR (P = 0.0144). Fibroblast growth factor binding protein 2 (FGFBP2) was significant in microarray (P = 0.013) and highly significant in qRT-PCR (P = 0.00162). The Fc receptor-like 6 gene (FCRL6) was significant in both microarray (P = 0.010) and qRT-PCR (P = 0.00335).
We carried out the qRT-PCR of Toll-like receptor 4 (TLR4) as previous studies have suggested its direct or indirect role in CNP (Hutchinson et al., 2009; Shah & Choi, 2017; Sorge et al., 2011). In the microarray, TLR4 was overexpressed in CNP patients (P = 0.036) and showed a similar significance in CNP vs control qRT-PCR analysis (P = 0.0368) but was not significant when an FDR cut-off of 5% was applied (Supplemental Fig. 6, Supplemental Table 5). GSK3B was identified by IPA analysis of microarray data (Fig. 4) and previous studies have suggested its role in CNP (Gobrecht et al., 2014; Maixner & Weng, 2013). In the present work, CNP vs control differential expression of GSK3B was non-significant at the transcriptional level both in the microarray and qRT-PCR (Supplemental Fig. 6, Supplemental Table 5). IPA suggested signal transducer and activator of transcription 1 and 3 (STAT1 and STAT3) and MYC as important transcription factors in our dataset. STAT1 and MYC were significantly upregulated (P = 0.001 for both) in the patients with CNP compared to the controls whilst STAT3 did not show any significant differential expression (Supplemental Fig. 6, Supplemental Table 5).
We carried out a series of statistical analyses of qRT-PCR gene expression data from all participants. The qRT-PCR data of the eighteen differentially expressed genes derived from the microarray data and TLR4, STAT1 and 3, GSK3B and MYC were included in this analysis. Analysis carried out between controls and all CNP samples with age and gender as control revealed WLS, CHTP1, CASP5, FGFBP2, STAT1, FCRL6, MYC, XCL2 and GZMA to be significantly associated with CNP under an FDR of 5% (P = 4.80 × 10–7, 7.74 × 10–7, 2.30 × 10–5, 0.0016, 0.0022, 0.00335, 0.00335, 0.0014 and 0.0168, respectively) (Supplemental Table 5).
We also carried out a three-arm analysis, with CNP grouped into two categories based on S-LANSS score cut-off of 12, and the control group used as the reference category. Ranking of p-values for multiple comparisons, under an FDR of 5%, revealed WLS, CHTP1, FGFBP2, FCRL6, SH2D1B, CASP5, KIR3DL2 and CXCR31 revealed to be significantly (P = 8.40 × 10–5, 7.89 × 10–4, 8.70 × 10–4, 0.002, 0.003, 0.004, 0.0084, 0.0136, respectively) associated with CNP with S-LANSS score ≥ 12 (Supplemental Table 6). However, none of the genes was significant with CNP with S-LANSS score < 12 (Supplemental Table 7). The genes SH2D1B, KIR3DL2 and CXCR31 were only associated with CNP samples with S-LANSS score ≥ 12.
A combination of expression data of genes significant between control and CNP groups that were also associated with the PI3-Akt pathway namely; MYC, STAT1, TLR4, CASP5 and WLS showed the AUROC of 0.852 (0.773, 0.931, 95% CI) suggesting that it could be used as a biomarker signature for CNP (Fig. 6a). The perturbations of these genes are robust to also compare high and low S-LANSS CNP patients (AUROC-0.819 (0.666, 0.973, 95% CI)) (Fig. 6b).

AUROC formed using WLS, MYC, STAT1, CASP5 and TLR4 gene expression between a control and all CNP patients and b high (≥ 12) and low (< 12) S-LANSS of CNP group. The combination of these gene expressions are robust enough to diagnose CNP
Area under the ROC curve (AUROC) analysis.
Effect of Medications on the Gene Expression
The series of ANCOVAs conducted on gene expression data using medication variables as predictors, revealed that anti-inflammatory, antidepressants and anticonvulsants drugs were all statistically significant at the 5% level in 1 out of 26 genes. These findings were consistent with a uniform distribution of P-values that would be expected from repeated instances of tests under a null hypothesis of no association. Hence, none of these variables were carried forward for inclusion in subsequent blocks. Opioid analgesics were statistically significant at the 5% level in 6 out of 26 genes. This finding was not consistent under a null hypothesis of no association, so this variable was carried forward for inclusion in the final blocks together with the grouping variable of CNP and the controlling variable age, gender and pain type (nociceptive and neuropathic pain).
Assuming an FDR of 5%, the genes TLR4 (P = 8.58 × 10–4), GSK3B (P = 0.00176) and KLRB1 (P = 0.00529) were significantly associated with the intake of opioid analgesics (Supplemental Table 8). The comparison of gene expression of TLR4 and GSK3B in the CNP patients showed that the expression of these genes was decreased in patients taking opioids against those not on opioid medications (Fig. 7). On the other hand, KLRB1 expression was higher in patients taking opioid medications.

In the box, red line shows the mean and pink and blue area indicate values within 95% confidence interval and standard deviation 1, respectively. The markers in the box indicate normalised ∆Ct values of the genes in the group. ∆Ct is inversely related to the gene expression. The no opioids and with opioids in the figure refer to the gene expression in patients without and with opioid medications. The statistically significant P-values are shown in the figure, **P < 0.01 and *P < 0.05
Comparison of TLR4, GSK3B and KLRB1 gene expression of CNP patients without and with opioids as the medication and controls.
Discussion and Conclusions
The screening of CNP is largely based on clinical diagnoses and questionnaires that have been used in the epidemiological studies (Bouhassira & Attal, 2011; Torrance et al., 2006). In the present study, our aim was to identify potential blood biomarkers for effective diagnoses and treatment of CNP. Blood biomarkers can also serve to identify potential perturbations in molecules and pathways that maybe linked to disease processes related to pain including in the CNS (Buckley et al., 2018; Yamamotova et al., 2010). We used a relatively homogeneous population for this study by excluding patients with cancer, fibromyalgia, osteoarthritis, diabetes and other complex metabolic disorders as these can change the landscape of expressed genes significantly and which may be correlated to CNP.
A critique of methodological limitations is necessary before discussing the main outcomes of the study. In our Affymetrix microarray results, the linear fold-change of most of the genes was between − 1.5 and 1.5. One reason for this could be that CNP and other nervous system disorders such as schizophrenia and autism are caused by subtle changes in many genes (Barnes et al., 2011; James, 2013). When comparing few genes with low fold-changes across a large number of genes, the calculated FDR values are very high (Tusher et al., 2001). Therefore, none of the genes in the CNP vs control comparison of microarray data could pass an FDR of 0.1. Also, each patient had a different medical history including ongoing medications. These medications can lead to variation within the group and affect the average value of gene expression in the group. Therefore, we have used a large sample set for confirming the gene perturbations by qRT-PCR and used a rigorous statistical approach for the analysis of qRT-PCR data.
Despite these limitations, our study provides some interesting results. The most significantly perturbed genes in CNP samples were associated with inflammation ascertaining that the state of inflammation was maintained in all the pain patients. This has also been observed in the recent studies carried out using human neural tissues of CNP patients (North et al., 2019; Tavares-Ferreira et al., 2019). The fact that inflammation-related perturbations could be detected in the blood of CNP samples in this study establishes that inflammation is a hallmark of CNP, and that blood is not only a source of tissue can not only provide easily accessible, but also potential insights into disease processes. The genes CHTP1, WLS, MYC and CASP5 that were significant in all CNP samples are associated with inflammation. CHPT1 regulates phosphatidylcholine biosynthesis and its involvement in pain manifestation has yet not been demonstrated (Jia et al., 2016). On the other hand, indirect roles of WLS and MYC in inflammation have been suggested (Chen et al., 2018). WLS regulates secretion and function of Wnt proteins which are crucial for neuronal development (Patapoutian & Reichardt, 2000). WLS interacts with mu-opioid receptor (MOR) and it has been suggested that in the presence of opioids, the interaction of WLS with MOR can lead to decreased Wnt secretion further causing decreased neurogenesis (Jin et al., 2010). WLS can also lead to inflammation by activating NF-κB signalling (Wang et al., 2012a, 2012b). A potential role of MYC in inflammation has also been suggested (Descalzi et al., 2017; Liu et al., 2015; Sipos et al., 2016). CASP5 is a proinflammatory caspase linked to the formation of inflammasome and is upregulated in various neuroinflammatory conditions including multiple sclerosis and osteoarthritis (An et al., 2020; Venero et al., 2013). Previous studies, including one from our group, have shown role of caspases and CASP5 in CNP (Buckley et al., 2018; Joseph & Levine, 2004).
The three-arm analysis with CNP separated into two groups based on S-LANSS scores (SLANSS score 12 as a cut-off) and control group as a reference showed eight genes to be significantly associated with CNP with S-LANSS score ≥ 12. These also include WLS, CHTP1, FGFBP2, FCRL6 and CASP5 which are upregulated in all CNP samples as well (Supplemental Tables 5 and 6). The additional genes associated only with CNP with S-LANNS ≥ 12 are SH2D1B, KIR3DL2 and CXCR31 (Supplemental Table 6).
The genes STAT1 and FCRL6 were significantly upregulated in the CNP compared to the controls (Supplemental Table 5). STAT1 is the downstream target of IFN-γ and also regulates expression of many genes that cause inflammation, survival of the cell, viability or pathogen response (Busch-Dienstfertig & González-Rodríguez, 2013; Kim et al., 2015; Tsuda et al., 2009). STAT1 expression has been found to increase in microglia of SNL compared to sham rats (Denk et al., 2016). Also, there is growing evidence to suggest that STAT3 activation is one of the key mediators of inflammation and CNP (Tsuda et al., 2011; Xue et al., 2014). In the present study, STAT3 perturbation was not significant in any analysis (Supplemental Tables 5–7,). It could be possible that CNP and STAT3 correlation could be more significant at the protein level as STAT proteins are regulated by tyrosine phosphorylation (Lim & Cao, 2006). FCRL6 is a cell surface glycoprotein which is selectively expressed by cytotoxic T-cells and natural killer (NK) cells (Rostamzadeh et al., 2018). It is upregulated in diseases characterised by chronic immune inflammation (Rostamzadeh et al., 2018) although its role in pain has not yet been validated.
FGFBP2, XCL2 and GZMA were downregulated in CNP. These proteins are related to the immune response. FGFBP2 is a serum protein that is selectively secreted by cytotoxic lymphocytes and may be involved in cytotoxic lymphocyte-mediated immunity (Ogawa et al., 2001). FGFBP2 downregulation has been associated with idiopathic frozen shoulders and developing ankylosing spondylitis (Fang et al., 2015; Hagiwara et al., 2012). XCL2 is a chemokine, and increased activity of chemokines is suggested to directly or indirectly contribute to CNP (Ji et al., 2014; Kwiatkowski & Mika, 2018; White et al., 2007; Zychowska et al., 2016). Interestingly, we found that the XCL2 was downregulated in CNP compared to controls. Further investigation would be needed to determine whether the expression of XCL2 was reflective of CNP or a response to drug.
GZMA is a serine protease present constitutively in the cytotoxic T-cells and NK cells. It acts through a caspase-independent pathway by inducing reactive oxygen species and targets infected cells as well as tumour cells (Rchiad et al., 2020; Zhou et al., 2020). GZMA has been associated with the regulation of inflammation and GZMA-deficient animal cells have shown increased levels of proinflammatory cytokines such as TNF-α (Garcia-Laorden et al., 2016).
Three additional genes, SH2D1B, KIR3DL2 and CXCR31, significant in only CNP samples with S-LANSS score ≥ 12, are also associated with immune response. The expression of these genes was also decreased in CNP samples. In summary, the profile of differentially expressed genes suggests that CNP patients have increased inflammation and a perturbed immune system (Baddack-Werncke et al., 2017; Costigan et al., 2009). In common with many of the other diseases are several potential confounding factors that might influence the results of our study. Perhaps the most difficult to correct for is depression suggested by a high-PHQ-9 score in CNP patients (Table 1). Hence, we cannot exclude the possibility that some changes in the gene expression could be due to underlying depression. For example, along with CNP overexpression of GSK3B has also been widely linked to anxiety, depression, neurological and neurodegenerative disorders (Beurel et al., 2015; Chen et al., 2015; Gobrecht et al., 2014; Liu et al., 2017; Maixner & Weng, 2013; Mazzardo-Martins et al., 2012; Ronai et al., 2014), possibly through neuroinflammation (Beurel et al., 2015; Jope et al., 2007; Kremer et al., 2011).
When comparing control and CNP samples, the AUROC curve analysis that functions as a clinical risk prediction model, and showed that the combination of MYC, STAT1, TLR4, CASP5 and WLS gene expression has a high sensitivity as well as specificity and thus considered a strong biomarker for CNP (Fig. 6a). These genes were robust enough to distinguish high and low S-LANSS CNP samples (Fig. 6b). All these genes are associated with PI3k-Akt pathway suggesting the involvement of this pathway in the pathogenesis of CNP.
We observed that expression of GSK3B, TLR4 and KLRB1 varies with the opioid intake (Fig. 7 and Supplemental Table 8). This may reflect the broad-spectrum analgesic actions of the opioids (Smith, 2012). It is well established that opioids can interact with TLR4 and GSK3B (Maixner & Weng, 2013; Shah & Choi, 2017). Interaction of morphine and other opioids with TLR4 has been shown to activate TLR4 pathway, resulting in the release of cytokines that can exacerbate inflammation leading to a state of hyperalgesia (Wang et al., 2012a, 2012b). In the present study, the expression of both TLR4 and GSK3B were reduced whilst the expression of KLRB1 was increased in CNP patients taking opioid medication compared to the patients that were not taking any opioid medication (Fig. 6). KLRB1 belongs to a lectin superfamily group that binds to other proteins and are calcium-dependent (Kirkham & Carlyle, 2014). Similar to GSK3B and TLR4, KLRB1 are also involved in PI3k-Akt pathway (Kirkham & Carlyle, 2014). Previous reports suggest that opioids activate TLR4 pathway of inflammation but their effect on TLR4 expression is not clear (El-Hage et al., 2011; Shah & Choi, 2017; Wang et al., 2012a, 2012b). Franchi et al. have shown that TLR4 mRNA expression was decreased in murine macrophages due to the activation of the Mu-opioid receptor (Franchi et al., 2012). A similar mechanism could be possible here, although there are various limitations to this conclusion; firstly, other medications can also affect TLR4 expression. Secondly, nearly all studies investigating the association between TLR4 and opioids have been carried out on brain cells, whereas our study used blood samples. The possibility that TLR4 shows different tissue-specific response to the opioids cannot be ruled out. Thirdly, the number of patients with and without opioids was not equal (33 vs 17) in the CNP cohort of our study. Nevertheless, it is an interesting outcome and we aim to investigate the opioid effect on the TLR4 expression on a larger cohort in the future.
Our study shows that GSK3B could be perturbed in CNP. Recent studies suggested that GSK3B levels are elevated in CNP (Maixner & Weng, 2013; Martins et al., 2011; Mazzardo-Martins et al., 2012). We observed that opioids decreased GSK3B expression in the patients. Previous studies have also shown that opioids like morphine can inhibit GSK3B in cancer cells and rat microglia (Xie et al., 2010; Zhao et al., 2009). However, effects of opioids on GSK3B requires further investigation for long-term implications on patients as GSK3B itself is a tightly regulated protein and master regulator of key neuronal signalling proteins (Beurel et al., 2015). We could not carry out protein analysis on the present samples as GSK3B could not be detected in the circulating plasma. However, it remains a key molecule for investigation for our future studies on CNP.
In conclusion, our results demonstrated that MYC, STAT1, TLR4, CASP5 and WLS gene expression function as strong clinical risk predictors and could be purposed as a potential biomarker signature for CNP. The effects of confounding factors, i.e. medications and depression cannot be fully ruled out in patient samples. As our study has been carried out on the patients rather than animal models, it provides us with an actual outlook of these potential biomarkers that could provide insight into CNP. We aim to validate our findings and evaluate the clinical utility of the potential predictive and prognostic biomarkers identified.
References
An, S., Hu, H., Li, Y., & Hu, Y. (2020). Pyroptosis plays a role in osteoarthritis. Aging and Disease, 11(5), 1146–1157. https://doi.org/10.14336/AD.2019.1127
Backryd, E. (2015). Pain in the blood? Envisioning mechanism-based diagnoses and biomarkers in clinical pain medicine. Diagnostics (basel), 5(1), 84–95. https://doi.org/10.3390/diagnostics5010084
Baddack-Werncke, U., Busch-Dienstfertig, M., Gonzalez-Rodriguez, S., Maddila, S. C., Grobe, J., Lipp, M., Stein, C., & Muller, G. (2017). Cytotoxic T cells modulate inflammation and endogenous opioid analgesia in chronic arthritis. Journal of Neuroinflammation, 14(1), 30. https://doi.org/10.1186/s12974-017-0804-y
Barabasi, A. L., Gulbahce, N., & Loscalzo, J. (2011). Network medicine: A network-based approach to human disease. Nature Reviews Genetics, 12(1), 56–68. https://doi.org/10.1038/nrg2918
Barnes, M. R., Huxley-Jones, J., Maycox, P. R., Lennon, M., Thornber, A., Kelly, F., Bates, S., Taylor, A., Reid, J., Jones, N., Schroeder, J., Scorer, C. A., Davies, C., Hagan, J. J., Kew, J. N., Angelinetta, C., Akbar, T., Hirsch, S., Mortimer, A. M., … de Belleroche, J. (2011). Transcription and pathway analysis of the superior temporal cortex and anterior prefrontal cortex in schizophrenia. Journal of Neuroscience Research, 89(8), 1218–1227. https://doi.org/10.1002/jnr.22647
Bennett, M. I., Smith, B. H., Torrance, N., & Potter, J. (2005). The S-LANSS score for identifying pain of predominantly neuropathic origin: validation for use in clinical and postal research. Journal of Pain, 6(3), 149–158. https://doi.org/10.1016/j.jpain.2004.11.007
Beurel, E., Grieco, S. F., & Jope, R. S. (2015). Glycogen synthase kinase-3 (GSK3): Regulation, actions, and diseases. Pharmacology & Therapeutics, 148, 114–131. https://doi.org/10.1016/j.pharmthera.2014.11.016
Boucher, T. J., & McMahon, S. B. (2001). Neurotrophic factors and neuropathic pain. Current Opinion in Pharmacology Journal, 1(1), 66–72.
Bouhassira, D., & Attal, N. (2011). Diagnosis and assessment of neuropathic pain: the saga of clinical tools. Pain, 152(3 Suppl), S74-83. https://doi.org/10.1016/j.pain.2010.11.027
Buckley, D. A., Jennings, E. M., Burke, N. N., Roche, M., McInerney, V., Wren, J. D., Finn, D. P., & McHugh, P. C. (2018). The development of translational biomarkers as a tool for improving the understanding, diagnosis and treatment of chronic neuropathic pain. Molecular Neurobiology, 55(3), 2420–2430. https://doi.org/10.1007/s12035-017-0492-8
Busch-Dienstfertig, M., & González-Rodríguez, S. (2013). IL-4, JAK-STAT signaling, and pain. JAK-STAT, 2(4), e27638. https://doi.org/10.4161/jkst.27638
Campbell, J. N., & Meyer, R. A. (2006). Mechanisms of neuropathic pain. Neuron, 52(1), 77–92. https://doi.org/10.1016/j.neuron.2006.09.021
Carniglia, L., Ramirez, D., Durand, D., Saba, J., Turati, J., Caruso, C., Scimonelli, T. N., & Lasaga, M. (2017). Neuropeptides and microglial activation in inflammation, pain, and neurodegenerative diseases. Mediators of Inflammation, 2017, 5048616. https://doi.org/10.1155/2017/5048616
Chen, C., Bao, G. F., Xu, G., Sun, Y., & Cui, Z. M. (2018). Altered Wnt and NF-kappaB signaling in facet joint osteoarthritis: Insights from RNA deep sequencing. Tohoku Journal of Experimental Medicine, 245(1), 69–77. https://doi.org/10.1620/tjem.245.69
Chen, J., Wang, M., Waheed Khan, R. A., He, K., Wang, Q., Li, Z., Shen, J., Song, Z., Li, W., Wen, Z., Jiang, Y., Xu, Y., Shi, Y., & Ji, W. (2015). The GSK3B gene confers risk for both major depressive disorder and schizophrenia in the Han Chinese population. Journal of Affective Disorders, 185, 149–155. https://doi.org/10.1016/j.jad.2015.06.040
Colloca, L., Ludman, T., Bouhassira, D., Baron, R., Dickenson, A. H., Yarnitsky, D., Freeman, R., Truini, A., Attal, N., Finnerup, N. B., Eccleston, C., Kalso, E., Bennett, D. L., Dworkin, R. H., & Raja, S. N. (2017). Neuropathic pain. Nature Reviews. Disease Primers, 3, 17002. https://doi.org/10.1038/nrdp.2017.2
Costigan, M., Moss, A., Latremoliere, A., Johnston, C., Verma-Gandhu, M., Herbert, T. A., Barrett, L., Brenner, G. J., Vardeh, D., Woolf, C. J., & Fitzgerald, M. (2009). T-cell infiltration and signaling in the adult dorsal spinal cord is a major contributor to neuropathic pain-like hypersensitivity. Journal of Neuroscience, 29(46), 14415–14422. https://doi.org/10.1523/JNEUROSCI.4569-09.2009
Dallas, P. B., Gottardo, N. G., Firth, M. J., Beesley, A. H., Hoffmann, K., Terry, P. A., Freitas, J. R., Boag, J. M., Cummings, A. J., & Kees, U. R. (2005). Gene expression levels assessed by oligonucleotide microarray analysis and quantitative real-time RT-PCR—How well do they correlate? BMC Genomics, 6, 59. https://doi.org/10.1186/1471-2164-6-59
Denk, F., Crow, M., Didangelos, A., Lopes, D. M., & McMahon, S. B. (2016). Persistent alterations in microglial enhancers in a model of chronic pain. Cell Reports, 15(8), 1771–1781. https://doi.org/10.1016/j.celrep.2016.04.063
Descalzi, G., Mitsi, V., Purushothaman, I., Gaspari, S., Avrampou, K., Loh, Y. E., Shen, L., & Zachariou, V. (2017). Neuropathic pain promotes adaptive changes in gene expression in brain networks involved in stress and depression. Science Signaling. https://doi.org/10.1126/scisignal.aaj1549
Dorsey, S. G., Renn, C. L., Griffioen, M., Lassiter, C. B., Zhu, S., Huot-Creasy, H., McCracken, C., Mahurkar, A., Shetty, A. C., Jackson-Cook, C. K., Kim, H., Henderson, W. A., Saligan, L., Gill, J., Colloca, L., Lyon, D. E., & Starkweather, A. R. (2019). Whole blood transcriptomic profiles can differentiate vulnerability to chronic low back pain. PLoS ONE, 14(5), e0216539. https://doi.org/10.1371/journal.pone.0216539
El-Hage, N., Podhaizer, E. M., Sturgill, J., & Hauser, K. F. (2011). Toll-like receptor expression and activation in astroglia: Differential regulation by HIV-1 Tat, gp120, and morphine. Immunological Investigations, 40(5), 498–522. https://doi.org/10.3109/08820139.2011.561904
Ellis, A., & Bennett, D. L. (2013). Neuroinflammation and the generation of neuropathic pain. British Journal of Anaesthesia, 111(1), 26–37. https://doi.org/10.1093/bja/aet128
Fang, F., Pan, J., Xu, L., Li, G., & Wang, J. (2015). Identification of potential transcriptomic markers in developing ankylosing spondylitis: A meta-analysis of gene expression profiles. BioMed Research International, 2015, 826316. https://doi.org/10.1155/2015/826316
Franchi, S., Moretti, S., Castelli, M., Lattuada, D., Scavullo, C., Panerai, A. E., & Sacerdote, P. (2012). Mu opioid receptor activation modulates Toll like receptor 4 in murine macrophages. Brain, Behavior, and Immunity, 26(3), 480–488. https://doi.org/10.1016/j.bbi.2011.12.010
Garcia-Laorden, M. I., Stroo, I., Blok, D. C., Florquin, S., Medema, J. P., de Vos, A. F., & van der Poll, T. (2016). Granzymes A and B regulate the local inflammatory response during Klebsiella pneumoniae pneumonia. Journal of Innate Immunity, 8(3), 258–268. https://doi.org/10.1159/000443401
Gobrecht, P., Leibinger, M., Andreadaki, A., & Fischer, D. (2014). Sustained GSK3 activity markedly facilitates nerve regeneration. Nature Communications, 5, 4561. https://doi.org/10.1038/ncomms5561
Hagiwara, Y., Ando, A., Onoda, Y., Takemura, T., Minowa, T., Hanagata, N., Tsuchiya, M., Watanabe, T., Chimoto, E., Suda, H., Takahashi, N., Sugaya, H., Saijo, Y., & Itoi, E. (2012). Coexistence of fibrotic and chondrogenic process in the capsule of idiopathic frozen shoulders. Osteoarthritis Cartilage, 20(3), 241–249. https://doi.org/10.1016/j.joca.2011.12.008
Hans, G., Deseure, K., & Adriaensen, H. (2008). Endothelin-1-induced pain and hyperalgesia: A review of pathophysiology, clinical manifestations and future therapeutic options. Neuropeptides, 42(2), 119–132. https://doi.org/10.1016/j.npep.2007.12.001
Hartung, J. E., Eskew, O., Wong, T., Tchivileva, I. E., Oladosu, F. A., O’Buckley, S. C., & Nackley, A. G. (2015). Nuclear factor-kappa B regulates pain and COMT expression in a rodent model of inflammation. Brain, Behavior, and Immunity, 50, 196–202. https://doi.org/10.1016/j.bbi.2015.07.014
Hoffman, E. M., Watson, J. C., St Sauver, J., Staff, N. P., & Klein, C. J. (2017). Association of long-term opioid therapy with functional status, adverse outcomes, and mortality among patients with polyneuropathy. JAMA of Neurology, 74(7), 773–779. https://doi.org/10.1001/jamaneurol.2017.0486
Hutchinson, M. R., Ramos, K. M., Loram, L. C., Wieseler, J., Sholar, P. W., Kearney, J. J., Lewis, M. T., Crysdale, N. Y., Zhang, Y., Harrison, J. A., Maier, S. F., Rice, K. C., & Watkins, L. R. (2009). Evidence for a role of heat shock protein-90 in toll like receptor 4 mediated pain enhancement in rats. Neuroscience, 164(4), 1821–1832. https://doi.org/10.1016/j.neuroscience.2009.09.046
Irizarry, R. A., Bolstad, B. M., Collin, F., Cope, L. M., Hobbs, B., & Speed, T. P. (2003). Summaries of affymetrix GeneChip probe level data. Nucleic Acids Research, 31(4), e15.
James, S. (2013). Human pain and genetics: Some basics. British Journal of Pain, 7(4), 171–178. https://doi.org/10.1177/2049463713506408
Jeong, H., Tombor, B., Albert, R., Oltvai, Z. N., & Barabási, A. L. (2000). The large-scale organization of metabolic networks. Nature, 407, 651. https://doi.org/10.1038/35036627
Ji, R. R., Xu, Z. Z., & Gao, Y. J. (2014). Emerging targets in neuroinflammation-driven chronic pain. Nature Reviews Drug Discovery, 13(7), 533–548. https://doi.org/10.1038/nrd4334
Jia, M., Andreassen, T., Jensen, L., Bathen, T. F., Sinha, I., Gao, H., Zhao, C., Haldosen, L. A., Cao, Y., Girnita, L., Moestue, S. A., & Dahlman-Wright, K. (2016). Estrogen receptor alpha promotes breast cancer by reprogramming choline metabolism. Cancer Research, 76(19), 5634–5646. https://doi.org/10.1158/0008-5472.CAN-15-2910
Jin, J., Kittanakom, S., Wong, V., Reyes, B. A., Van Bockstaele, E. J., Stagljar, I., Berrettini, W., & Levenson, R. (2010). Interaction of the mu-opioid receptor with GPR177 (Wntless) inhibits Wnt secretion: potential implications for opioid dependence. BMC Neuroscience, 11, 33. https://doi.org/10.1186/1471-2202-11-33
Jope, R. S., Yuskaitis, C. J., & Beurel, E. (2007). Glycogen synthase kinase-3 (GSK3): Inflammation, diseases, and therapeutics. Neurochemical Research, 32(4–5), 577–595. https://doi.org/10.1007/s11064-006-9128-5
Joseph, E. K., & Levine, J. D. (2004). Caspase signalling in neuropathic and inflammatory pain in the rat. European Journal of Neuroscience, 20(11), 2896–2902. https://doi.org/10.1111/j.1460-9568.2004.03750.x
Kelleher, J. H., Tewari, D., & McMahon, S. B. (2017). Neurotrophic factors and their inhibitors in chronic pain treatment. Neurobiology of Disease, 97, 127–138. https://doi.org/10.1016/j.nbd.2016.03.025
Kim, H. S., Kim, D. C., Kim, H. M., Kwon, H. J., Kwon, S. J., Kang, S. J., Kim, S. C., & Choi, G. E. (2015). STAT1 deficiency redirects IFN signalling toward suppression of TLR response through a feedback activation of STAT3. Scientific Reports, 5, 13414. https://doi.org/10.1038/srep13414
Kirkham, C. L., & Carlyle, J. R. (2014). Complexity and diversity of the NKR-P1: Clr (Klrb1:Clec2) recognition systems. Frontiers in Immunology, 5, 214. https://doi.org/10.3389/fimmu.2014.00214
Kramer, A., Green, J., Pollard, J., Jr., & Tugendreich, S. (2014). Causal analysis approaches in Ingenuity Pathway Analysis. Bioinformatics, 30(4), 523–530. https://doi.org/10.1093/bioinformatics/btt703
Kremer, A., Louis, J. V., Jaworski, T., & Van Leuven, F. (2011). GSK3 and Alzheimer’s disease: Facts and fiction. Frontiers in Molecular Neuroscience, 4, 17. https://doi.org/10.3389/fnmol.2011.00017
Kwiatkowski, K., & Mika, J. (2018). The importance of chemokines in neuropathic pain development and opioid analgesic potency. Pharmacological Reports, 70(4), 821–830. https://doi.org/10.1016/j.pharep.2018.01.006
Lasselin, J., Kemani, M. K., Kanstrup, M., Olsson, G. L., Axelsson, J., Andreasson, A., Lekander, M., & Wicksell, R. K. (2016). Low-grade inflammation may moderate the effect of behavioral treatment for chronic pain in adults. Journal of Behavioral Medicine, 39(5), 916–924. https://doi.org/10.1007/s10865-016-9769-z
Latremoliere, A., & Costigan, M. (2011). GCH1, BH4 and pain. Current Pharmaceutical Biotechnology, 12(10), 1728–1741.
Latremoliere, A., & Costigan, M. (2018). Combining human and rodent genetics to identify new analgesics. Neuroscience Bulletin, 34(1), 143–155. https://doi.org/10.1007/s12264-017-0152-z
Lawrence, T. (2009). The nuclear factor NF-kappaB pathway in inflammation. Cold Spring Harbor Perspectives in Biology, 1(6), a001651. https://doi.org/10.1101/cshperspect.a001651
Lei, W., Mullen, N., McCarthy, S., Brann, C., Richard, P., Cormier, J., Edwards, K., Bilsky, E. J., & Streicher, J. M. (2017). Heat-shock protein 90 (Hsp90) promotes opioid-induced anti-nociception by an ERK mitogen-activated protein kinase (MAPK) mechanism in mouse brain. Journal of Biological Chemistry, 292(25), 10414–10428. https://doi.org/10.1074/jbc.M116.769489
Lim, C. P., & Cao, X. (2006). Structure, function, and regulation of STAT proteins. Molecular BioSystems, 2(11), 536–550. https://doi.org/10.1039/b606246f
Liu, S., Wang, L., Sun, N., Yang, C., Liu, Z., Li, X., Cao, X., Xu, Y., & Zhang, K. (2017). The gender-specific association of rs334558 in GSK3beta with major depressive disorder. Medicine (baltimore), 96(3), e5928. https://doi.org/10.1097/MD.0000000000005928
Liu, T., Zhou, Y., Ko, K. S., & Yang, H. (2015). Interactions between Myc and mediators of inflammation in chronic liver diseases. Mediators of Inflammation, 2015, 276850. https://doi.org/10.1155/2015/276850
Livak, K. J., & Schmittgen, T. D. (2001). Analysis of relative gene expression data using real-time quantitative PCR and the 2(-Delta Delta C(T)) method. Methods, 25(4), 402–408. https://doi.org/10.1006/meth.2001.1262
Lopes, D. M., Malek, N., Edye, M., Jager, S. B., McMurray, S., McMahon, S. B., & Denk, F. (2017). Sex differences in peripheral not central immune responses to pain-inducing injury. Scientific Reports, 7(1), 16460. https://doi.org/10.1038/s41598-017-16664-z
Maixner, D. W., & Weng, H. R. (2013). The role of glycogen synthase kinase 3 beta in neuroinflammation and pain. Journal of Pharmacy and Pharmacology (los Angel), 1(1), 001. https://doi.org/10.13188/2327-204X.1000001
Martins, D. F., Rosa, A. O., Gadotti, V. M., Mazzardo-Martins, L., Nascimento, F. P., Egea, J., Lopez, M. G., & Santos, A. R. (2011). The antinociceptive effects of AR-A014418, a selective inhibitor of glycogen synthase kinase-3 beta, in mice. Journal of Pain, 12(3), 315–322. https://doi.org/10.1016/j.jpain.2010.06.007
Mazzardo-Martins, L., Martins, D. F., Stramosk, J., Cidral-Filho, F. J., & Santos, A. R. (2012). Dec 13). Glycogen synthase kinase 3-specific inhibitor AR-A014418 decreases neuropathic pain in mice: Evidence for the mechanisms of action. Neuroscience, 226, 411–420. https://doi.org/10.1016/j.neuroscience.2012.09.020
Morey, J. S., Ryan, J. C., & Van Dolah, F. M. (2006). Microarray validation: Factors influencing correlation between oligonucleotide microarrays and real-time PCR. Biological Procedures Online, 8, 175–193. https://doi.org/10.1251/bpo126
North, R. Y., Li, Y., Ray, P., Rhines, L. D., Tatsui, C. E., Rao, G., Johansson, C. A., Zhang, H., Kim, Y. H., Zhang, B., Dussor, G., Kim, T. H., Price, T. J., & Dougherty, P. M. (2019). Electrophysiological and transcriptomic correlates of neuropathic pain in human dorsal root ganglion neurons. Brain, 142(5), 1215–1226. https://doi.org/10.1093/brain/awz063
Ogawa, K., Tanaka, K., Ishii, A., Nakamura, Y., Kondo, S., Sugamura, K., Takano, S., Nakamura, M., & Nagata, K. (2001). A novel serum protein that is selectively produced by cytotoxic lymphocytes. The Journal of Immunology, 166(10), 6404–6412. https://doi.org/10.4049/jimmunol.166.10.6404
Patapoutian, A., & Reichardt, L. F. (2000). Roles of Wnt proteins in neural development and maintenance. Current Opinion in Neurobiology, 10(3), 392–399.
Rchiad, Z., Haidar, M., Ansari, H. R., Tajeri, S., Mfarrej, S., Ben Rached, F., Kaushik, A., Langsley, G., & Pain, A. (2020). Novel tumour suppressor roles for GZMA and RASGRP1 in Theileria annulata-transformed macrophages and human B lymphoma cells. Cell Microbiology, 22(12), e13255. https://doi.org/10.1111/cmi.13255
Ronai, Z., Kovacs-Nagy, R., Szantai, E., Elek, Z., Sasvari-Szekely, M., Faludi, G., Benkovits, J., Rethelyi, J. M., & Szekely, A. (2014). Glycogen synthase kinase 3 beta gene structural variants as possible risk factors of bipolar depression. American Journal of Medical Genetics B, 165B(3), 217–222. https://doi.org/10.1002/ajmg.b.32223
Rostamzadeh, D., Kazemi, T., Amirghofran, Z., & Shabani, M. (2018). Update on Fc receptor-like (FCRL) family: New immunoregulatory players in health and diseases. Expert Opinion on Therapeutic Targets, 22(6), 487–502. https://doi.org/10.1080/14728222.2018.1472768
Shah, M., & Choi, S. (2017). Toll-like receptor-dependent negative effects of opioids: a battle between analgesia and hyperalgesia [mini review]. Frontiers in Immunology. https://doi.org/10.3389/fimmu.2017.00642
Shih, R. H., Wang, C. Y., & Yang, C. M. (2015). NF-kappaB signaling pathways in neurological inflammation: A mini review. Frontiers in Molecular Neuroscience, 8, 77. https://doi.org/10.3389/fnmol.2015.00077
Sipos, F., Firneisz, G., & Muzes, G. (2016). Therapeutic aspects of c-MYC signaling in inflammatory and cancerous colonic diseases. World Journal of Gastroenterology, 22(35), 7938–7950. https://doi.org/10.3748/wjg.v22.i35.7938
Slenter, D. N., Kutmon, M., Hanspers, K., Riutta, A., Windsor, J., Nunes, N., Melius, J., Cirillo, E., Coort, S. L., Digles, D., Ehrhart, F., Giesbertz, P., Kalafati, M., Martens, M., Miller, R., Nishida, K., Rieswijk, L., Waagmeester, A., Eijssen, L. M. T., … Willighagen, E. L. (2018). WikiPathways: a multifaceted pathway database bridging metabolomics to other omics research. Nucleic Acids Research, 46(D1), D661–D667. https://doi.org/10.1093/nar/gkx1064
Smith, H. S. (2012). Opioids and neuropathic pain. Pain Physician, 15(3S), ES93–ES110.
Sommer, C., Leinders, M., & Uceyler, N. (2018). Inflammation in the pathophysiology of neuropathic pain. Pain, 159(3), 595–602. https://doi.org/10.1097/j.pain.0000000000001122
Sorge, R. E., LaCroix-Fralish, M. L., Tuttle, A. H., Sotocinal, S. G., Austin, J. S., Ritchie, J., Chanda, M. L., Graham, A. C., Topham, L., Beggs, S., Salter, M. W., & Mogil, J. S. (2011). Spinal cord Toll-like receptor 4 mediates inflammatory and neuropathic hypersensitivity in male but not female mice. Journal of Neuroscience, 31(43), 15450–15454. https://doi.org/10.1523/JNEUROSCI.3859-11.2011
Szklarczyk, D., Morris, J. H., Cook, H., Kuhn, M., Wyder, S., Simonovic, M., Santos, A., Doncheva, N. T., Roth, A., Bork, P., Jensen, L. J., & von Mering, C. (2017). The STRING database in 2017: quality-controlled protein-protein association networks, made broadly accessible. Nucleic Acids Research, 45(D1), D362–D368. https://doi.org/10.1093/nar/gkw937
Tak, P. P., & Firestein, G. S. (2001). NF-kappaB: A key role in inflammatory diseases. Journal of Clinical Investigation, 107(1), 7–11. https://doi.org/10.1172/JCI11830
Tavares-Ferreira, D., Lawless, N., Bird, E. V., Atkins, S., Collier, D., Sher, E., Malki, K., Lambert, D. W., & Boissonade, F. M. (2019). Correlation of miRNA expression with intensity of neuropathic pain in man. Molecular Pain, 15, 1744806919860323. https://doi.org/10.1177/1744806919860323
Tegeder, I., Costigan, M., Griffin, R. S., Abele, A., Belfer, I., Schmidt, H., Ehnert, C., Nejim, J., Marian, C., Scholz, J., Wu, T., Allchorne, A., Diatchenko, L., Binshtok, A. M., Goldman, D., Adolph, J., Sama, S., Atlas, S. J., Carlezon, W. A., … Woolf, C. J. (2006). GTP cyclohydrolase and tetrahydrobiopterin regulate pain sensitivity and persistence. Nature Medicine, 12(11), 1269–1277. https://doi.org/10.1038/nm1490
Torrance, N., Smith, B. H., Bennett, M. I., & Lee, A. J. (2006). The epidemiology of chronic pain of predominantly neuropathic origin. Results from a general population survey. Journal of Pain, 7(4), 281–289. https://doi.org/10.1016/j.jpain.2005.11.008
Tsuda, M., Kohro, Y., Yano, T., Tsujikawa, T., Kitano, J., Tozaki-Saitoh, H., Koyanagi, S., Ohdo, S., Ji, R. R., Salter, M. W., & Inoue, K. (2011). JAK-STAT3 pathway regulates spinal astrocyte proliferation and neuropathic pain maintenance in rats. Brain, 134(4), 1127–1139. https://doi.org/10.1093/brain/awr025
Tsuda, M., Masuda, T., Kitano, J., Shimoyama, H., Tozaki-Saitoh, H., & Inoue, K. (2009). IFN-gamma receptor signaling mediates spinal microglia activation driving neuropathic pain. Proceedings of the National Academy of Sciences of the United States of America, 106(19), 8032–8037. https://doi.org/10.1073/pnas.0810420106
Tusher, V. G., Tibshirani, R., & Chu, G. (2001). Significance analysis of microarrays applied to the ionizing radiation response. Proceedings of the National Academy of Sciences of the United States of America, 98(9), 5116. https://doi.org/10.1073/pnas.091062498
Uceyler, N., & Sommer, C. (2012). Cytokine-related and histological biomarkers for neuropathic pain assessment. Pain Management, 2(4), 391–398. https://doi.org/10.2217/pmt.12.28
van Hecke, O., Austin, S. K., Khan, R. A., Smith, B. H., & Torrance, N. (2014). Neuropathic pain in the general population: A systematic review of epidemiological studies. Pain, 155(4), 654–662. https://doi.org/10.1016/j.pain.2013.11.013
Venero, J. L., Burguillos, M. A., & Joseph, B. (2013). Caspases playing in the field of neuroinflammation: Old and new players. Developmental Neuroscience, 35(2–3), 88–101. https://doi.org/10.1159/000346155
Wang, L. T., Wang, S. J., & Hsu, S. H. (2012a). Functional characterization of mammalian Wntless homolog in mammalian system. The Kaohsiung Journal of Medical Sciences, 28(7), 355–361. https://doi.org/10.1016/j.kjms.2012.02.001
Wang, X., Loram, L. C., Ramos, K., de Jesus, A. J., Thomas, J., Cheng, K., Reddy, A., Somogyi, A. A., Hutchinson, M. R., Watkins, L. R., & Yin, H. (2012b). Morphine activates neuroinflammation in a manner parallel to endotoxin. Proceedings of the National Academy of Sciences of the United States of America, 109(16), 6325–6330. https://doi.org/10.1073/pnas.1200130109
White, F. A., Jung, H., & Miller, R. J. (2007). Chemokines and the pathophysiology of neuropathic pain. Proceedings of the National Academy of Sciences of the United States of America, 104(51), 20151–20158. https://doi.org/10.1073/pnas.0709250104
Xie, N., Li, H., Wei, D., LeSage, G., Chen, L., Wang, S., Zhang, Y., Chi, L., Ferslew, K., He, L., Chi, Z., & Yin, D. (2010). Glycogen synthase kinase-3 and p38 MAPK are required for opioid-induced microglia apoptosis. Neuropharmacology, 59(6), 444–451. https://doi.org/10.1016/j.neuropharm.2010.06.006
Xue, Z. J., Shen, L., Wang, Z. Y., Hui, S. Y., Huang, Y. G., & Ma, C. (2014). STAT3 inhibitor WP1066 as a novel therapeutic agent for bCCI neuropathic pain rats. Brain Research, 1583, 79–88. https://doi.org/10.1016/j.brainres.2014.07.015
Yamamotova, A., Sramkova, T., & Rokyta, R. (2010). Intensity of pain and biochemical changes in blood plasma in spinal cord trauma. Spinal Cord, 48(1), 21–26. https://doi.org/10.1038/sc.2009.71
Zhao, M., Zhou, G., Zhang, Y., Chen, T., Sun, X., Stuart, C., Hanley, G., Li, J., Zhang, J., & Yin, D. (2009). beta-arrestin2 inhibits opioid-induced breast cancer cell death through Akt and caspase-8 pathways. Neoplasma, 56(2), 108–113.
Zhou, Z., He, H., Wang, K., Shi, X., Wang, Y., Su, Y., Wang, Y., Li, D., Liu, W., Zhang, Y., Shen, L., Han, W., Shen, L., Ding, J., & Shao, F. (2020). Granzyme A from cytotoxic lymphocytes cleaves GSDMB to trigger pyroptosis in target cells. Science. https://doi.org/10.1126/science.aaz7548
Zou, W., Zhan, X., Li, M., Song, Z., Liu, C., Peng, F., & Guo, Q. (2012). Identification of differentially expressed proteins in the spinal cord of neuropathic pain models with PKCgamma silence by proteomic analysis. Brain Research, 1440, 34–46. https://doi.org/10.1016/j.brainres.2011.12.046
Zychowska, M., Rojewska, E., Piotrowska, A., Kreiner, G., & Mika, J. (2016). Microglial inhibition influences XCL1/XCR1 expression and causes analgesic effects in a mouse model of diabetic neuropathy. Anesthesiology, 125(3), 573–589. https://doi.org/10.1097/ALN.0000000000001219
Acknowledgements
PCM would like to acknowledge funding support from the British Pain Society through the 2013 Mildred B. Clulow Award and the Centre for Biomarker Research. We would also like to acknowledge the Pain Management Services at Seacroft Hospital for their support in the collection of pain participant samples.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflict of interest to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Islam, B., Stephenson, J., Young, B. et al. The Identification of Blood Biomarkers of Chronic Neuropathic Pain by Comparative Transcriptomics. Neuromol Med 24, 320–338 (2022). https://doi.org/10.1007/s12017-021-08694-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12017-021-08694-8