
Abstract
Purpose
The World Health Organization Disability Assessment Schedule 2.0 (WHODAS 2.0) is a widely used disability-specific outcome measure. This study develops mapping algorithms to estimate Assessment of Quality of Life (AQoL)-4D utilities based on the WHODAS 2.0 responses to facilitate economic evaluation.
Methods
The study sample comprises people with disability or long-term conditions (n = 3376) from the 2007 Australian National Survey of Mental Health and Wellbeing. Traditional regression techniques (i.e., Ordinary Least Square regression, Robust MM regression, Generalised Linear Model and Betamix Regression) and machine learning techniques (i.e., Lasso regression, Boosted regression, Supported vector regression) were used. Five-fold internal cross-validation was performed. Model performance was assessed using a series of goodness-of-fit measures.
Results
The robust MM estimator produced the preferred mapping algorithm for the overall sample with the smallest mean absolute error in cross-validation (MAE = 0.1325). Different methods performed differently for different disability subgroups, with the subgroup with profound or severe restrictions having the highest MAE across all methods and models.
Conclusion
The developed mapping algorithm enables cost-utility analyses of interventions for people with disability where the WHODAS 2.0 has been collected. Mapping algorithms developed from different methods should be considered in sensitivity analyses in economic evaluations.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Preference-based quality-of-life data is increasingly collected for economic evaluation studies, such as cost-utility analysis (CUA), to compare value for money and prioritise limited resources. Quality-adjusted life years (QALYs) are the predominant outcome measure in CUAs, calculated using a preference-based multi-attribute utility instrument (MAUI) like EQ-5D [1, 2] and AQoL-4D to measure quality of life [3].
The QALY is the preferred outcome measure used by many government funding bodies, such as the National Institute for Health and Care Excellence (NICE) in the UK [4, 5] and the Pharmaceutical Benefits Advisory Committee (PBAC) in Australia [6]. However, in many disability studies, researchers still prefer to use a non-preference-based disability-specific instrument [7]. A recent review of disability outcome measures identified 20 generic instruments and reported that the World Health Organisation Disability Assessment Schedule (WHODAS) is widely used [8]; The 12-item version of the WHODAS 2.0 has been validated with people with different types of disabilities [9,10,11,12,13,14]. However, the summary score of WHODAS 2.0 is non-preference-based, which does not permit the construction of QALYs [8]. Mapping analysis estimates a statistical relationship between preference-based and non-preference-based instruments, the "next-best" approach to deriving health state utilities from a non-preference-based instrument [15].
No current study has developed mapping algorithms to generate health utility from WHODAS 2.0. Lokkerbol et al. [16] have estimated an algorithm for mapping WHODAS 2.0 (both 36 and 12 versions) to disability weights (i.e., to calculate Disability Adjusted Life Years) using data from the World Health Organisation (WHO) Multi-Country Survey Study on Health and Responsiveness (MCSS) [17]. But it included only eight out of the 12 questions of WHODAS 2.0 short form. This may impact the accuracy of the prediction if the missing items are significant predictors.
Traditional econometric methods such as ordinary least squares (OLS) and the generalised linear model (GLM) have been commonly used to create mapping algorithms [18, 19]. Specifying the optimal functional form is often difficult when complex non-linear relationships exist between the source and target instruments. Furthermore, the distribution of a MAUI is often skewed, bounded at one, and maybe multinomial, which adds further complexity to identifying the optimal mapping algorithm [20]. Recently, supervised machine learning techniques have increasingly been used in mapping studies as they have the potential to select important predictors and account for non-linear relationships more efficiently and effectively than traditional approaches. Gao et al. [21] used a deep neural network method to develop mapping algorithms from the MacNew Heart Disease Quality of Life Questionnaire onto different country-specific value sets of EQ-5D-5L (n = 943). They found that the machine learning technique performed similarly to the traditional econometric methods in three out of the four countries of their sample. Another study by Aghdaee et al. [22] also found that machine learning (e.g., Lasso regression) performed marginally better if not combined with other traditional econometric methods (n = 2015). Despite these previous findings, machine learning still has the advantage of determining the nature of the relationships without researchers trying to guess the possible combinations between them or imposing their bias on the results by selecting their preferred functional form. With a larger dataset than the previous studies, the performance of machine learning techniques in our study may improve.
The objective of the study is to derive optimal mapping algorithms from the 12-item version of WHODAS 2.0 (hereafter 'WHODAS') to the Assessment of Quality of Life-4 Dimension (AQoL-4D), which is a validated generic health-related preference-based instrument that is widely used in disability studies [23,24,25,26]. This present study also contributes to the mapping literature by comparing results from traditional econometric models to machine learning approaches.
Methods
This study follows the Mapping onto Preference-based measures reporting standards (MAPS) from the International Society for Pharmacoeconomics and Outcomes Research (ISPOR) to conduct and report mapping analyses [15]. To apply the machine learning techniques, we followed the steps and best practice recommendations from Doupe et al. [27]. All statistical analyses were conducted using Stata 16 except the exploratory factor analysis, which was performed using the EViews software version 12.
Data and sample
The data were obtained from the 2007 Australian National Survey of Mental Health and Wellbeing (NSMHWB). The 2007 NSMHWB was conducted throughout Australia from August to December 2007 on a national representative sample. Residences of private dwellings were randomly selected using a stratified, multistage area approach, and then one person meeting the age criteria of 16–85 years was selected from the dwelling. There were 14,805 eligible dwellings out of the initial 17,352 selected dwellings due to all residents being out of scope or empty dwellings. Finally, 8841 complete responses were recorded from the face-to-face interviews (60% response rate).
Both the WHODAS and AQoL-4D were included in this survey. Considering WHODAS is commonly used among people with disability, in our study, we constrained the study sample to be people who reported having a disability, regardless of whether they have a current restriction in activities or not (n = 3376). We also excluded a small proportion (n = 30) if they did not answer all of the WHODAS and the AQoL-4D items. The final study sample consists of 3376 respondents. The detailed sample selection process can be found in the flowchart in the Electronic supplementary materials (ESM) (ESM 1 Fig. S1).
Instruments
Source measure: WHODAS 2.0–12
The WHODAS is a disability-specific instrument in which all items use a five-point ordinal response scale (1 = None, 2 = Mild, 3 = Moderate, 4 = Severe, and 5 = Extreme/Cannot do). This instrument has a recall period of 30 days [28].
The WHODAS captures functioning in six domains, including cognitive (Items 3 and 6), mobility (Items 1 and 7), self-care (Items 8 and 9), getting along (Items 10 and 11), life activities (Item 2) and participation (Items 4 and 5). This study uses the widely used simple scoring method to calculate the WHODAS summary score, which is calculated as a sum of all items' raw scores [9, 14, 24]. The summary scores of the WHODAS, therefore, range from 12 (no disability) to 60 (full disability).
Target measure: AQoL-4D
AQoL-4D is a valid generic preference-based quality-of-life instrument [3, 29]. It contains 12 items (each with four response levels) and is evenly grouped into four dimensions (independent living, relationships, mental health and senses). This instrument has a recall period of seven days. The preference weight of AQoL-4D was developed using the time-trade-off approach among the Australian general public. The utilities range from -0.04 (worse than death) to 1 (full health).
More detailed comparisons of the domains and characteristics between the source (i.e., WHODAS) and the target measures (i.e., AQoL-4D) are presented in ESM 1 Table S1.
Statistical analysis
As previous literature suggested [30, 31], exploratory data analysis was first conducted to understand the degree of conceptual overlap between the two instruments, including Pearson correlation and exploratory factor analysis (EFA). The maximum likelihood factor analysis with a minimum average partial method was used to consider how many factors to retain in the factor analysis. Factors were rotated using the orthoblique promax method [32]. The EFA would provide a clear view of the underlying structures between the two instruments, the information of which is useful for checking the feasibility of conducting a mapping analysis as well as the potential WHODAS item selection when developing mapping algorithms using traditional econometric techniques.
We used a direct mapping approach to predict AQoL-4D from WHODAS items. Indirect response mapping, which has also been used in the mapping literature, particularly when predicting EQ-5D, was not considered. Unlike EQ-5D, in which only responses to five dimensions need to be estimated, to accurately predict AQoL-4D, researchers need to predict responses to 12 dimensions. There is a higher chance of predicting errors; in particular, the AQoL-4D include items not directly captured by WHODAS (see EMS Table).
We used four traditional econometric and three machine-learning techniques to develop mapping algorithms. The four traditional regression techniques have been widely used in the mapping literature [17, 19, 33,34,35,36]. They consist of (i) the ordinary least squares (OLS) estimator, which is the most widely used technique in the mapping literature; (ii) the robust MM estimator, which reduces the influence from potential outliers; (iii) the generalised linear model (GLM), which permits different combinations of distribution families and link functions, including non-normal distributions; and (iv) the beta mixture regression model which is suitable for analysing data with a continuous response variable that ranges from 0 to 1 and follows a beta distribution. Recently, the adjusted limited dependent variable mixture models (ALDVMM) have been developed that perform well with EQ-5D data [10, 37]. However, since AQoL-4D does not have a large gap between 1 and the next feasible value as EQ-5D-3L UK tariff does, this method is not applied in our study.
The following two basic model specifications were considered for predicting the AQoL utility (\(\mathrm{uAQoL}4\mathrm{D})\) using the item-level responses of WHODAS. Instead of treating a WHODAS item as a continuous variable, it was transformed into five indicator variables corresponding to each of the response levels. Using level 1 as the reference category, the mapping function therefore included four variables for each of the 12 WHODAS items, thereby allowing for the potential non-linear effects across different levels.
where \(\mathrm{uAQoL}4\mathrm{D}\) represents the predicted utility for the individual \(i\). \(\mathrm{WHODAS}\_\mathrm{Ite}{\mathrm{m}\_\mathrm{level}}_{ij}\) is the set of binary variables constructed from the response levels of the WHODAS items. For each item, there are five levels. Therefore, four dummies will be included, with the first level serving as a reference level. Age is in years, and Sex is a binary variable equal to 1 for males and 0 for females.
To ensure that the coefficients of the WHODAS items follow a monotonic pattern (i.e., more severe disability levels have larger or equal decrements compared to less severe levels), we imposed additional constraints in traditional regression models. This involved combining item levels or excluding items with positive coefficients during estimation.
In addition, we employed three machine learning techniques: (i) Lasso regression; (ii) Support vector regression (SVR); (iii) Boosted regression (Boosting), all of which can be applied to continuous outcomes. Lasso regression is a method that selects and fits covariates in a model that minimises prediction errors, using the "shrinkage" method that constrains less important parameters towards zero. The key benefit of lasso regression is that it can automatically perform variable selection, providing a simpler model with only the most relevant features. This can help reduce model complexity and improve generalisation performance on new data [37]. In support vector regression (SVR), the main objective is to find a function that best fits the data and minimises errors between the predicted and observed values. It is done by identifying an n-dimensional space (hyperplane) that lies at an optimal distance from the data points (aka., support vectors) [38]. Boosted regression enhances accuracy by combining predictions from multiple weaker models via a weighted average. It starts with base learners, which are typically shallow decision trees, and then trains multiple weak learners in an iterative manner. After each weak learner is trained, it combines the trained weak learners using a weighted scheme. Boosted regression excels in dealing with intricate, non-linear dependencies between features and the target variable. The amalgamation of multiple weak learners empowers the final boosted model, imparting robustness and achieving high predictive accuracy [1, 2].
Apart from Lasso regression, where it assumes a linear functional form as we specified the overarching model structure (3), the other techniques are data-driven and do not rely on strong assumptions about the possible function form. The relationships of the variables are determined by the machine learning algorithms. They could be linear or non-linear depending on the patterns and structures present in the dataset.
where \(\mathrm{uAQoL}4\mathrm{D}\) represents the predicted utility for the individual \(i\). \(\mathrm{WHODAS}\_\mathrm{Ite}{\mathrm{m}\_\mathrm{level}}_{ij}\) is the set of binary variables constructed from the response levels of the WHODAS items. For each item, there are five levels. Therefore, four dummies will be included, with the first level serving as a reference level. Age is in years, and Sex is a binary variable equal to 1 for males and 0 for females.
Assessing goodness-of-fit
We employed five-fold cross-validation to evaluate goodness-of-fit. The full sample was randomly split into five groups with equal observations, where 80% of the data were used for algorithm development and the remaining 20% for performance assessment. This process was repeated five times, with each group used four times for estimation and once for validation. The optimal model and method were selected based on the best goodness-of-fit test result from the pooled estimated errors in the absence of external validation data.
Three goodness-of-fit statistics were used: (i) the mean absolute error (MAE), (ii) the root mean square error (RMSE), and (iii) the intraclass correlation (ICC) using a random effect model. We selected MAE as the primary criterion because the MAE is the most natural and unambiguous measure of the average error magnitude, while the RMSE places more weight on outliers [39]. Additionally, we calculated the percentages of observations for which the difference between the observed and predicted values was larger than 0.03, which was performed in previous studies [36, 40]. We also considered the performance of predicting the lower and upper bound of AQoL-4D when selecting the optimal algorithm.
To use the predicted utility scores in real life, it is important to ensure that the final predictions fall within the theoretic boundary of the targeting instrument [19, 34, 41]. In our studies, the lower and upper values are truncated at − 0.04 and 1, respectively, to ensure the predicted value falls into the theoretical range.
The final mapping algorithms were developed using full-sample observations and are based on the method and model that perform the best in the five-fold cross-validation.
Assessing mapping performance among different disability restriction levels
It is a common observation from previous mapping studies that mapping functions could perform relatively poorly in predicting lower utilities [19, 36, 42]. We therefore reported the performance of different mapping algorithms on people with different disability restriction levels. Results from this sub-sample analysis provide useful information for users to better understand the direction and magnitudes of potential prediction bias.
We divided our sample into five subgroups, including people with profound or severe core restrictions, moderate core restrictions, mild core restrictions, school/employment restrictions, or no specific restrictions. We then performed two types of subgroup analysis. First, we calculated the goodness-of-fit statistics for each subgroup. In addition, we calculated the between-group margins of error in the predicted differences of average utilities between a particular subgroup with restrictions versus the subgroup with no specific restrictions.Footnote 1 This was conducted to assess how accurately the mapping algorithms capture the difference between different severity levels, which could represent incremental utilities across different disease states in economic evaluations.
Results
Descriptive analysis
Table 1 presents the descriptive characteristics of our study sample. Among 3376 people with disability in our sample, the mean age was 54 (SD = 19), and 51% were female. About 3% reported profound core activity restrictions, 58% reported having no specific restrictions, and 7% and 19% reported having excellent physical or mental health, respectively. The mean AQoL-4D utility was 0.70 (SD = 0.26), and the mean WHODAS 2.0–12 total score was 18 (SD = 7).
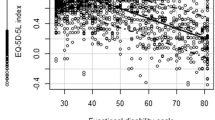
The distribution of the AQoL-4D utilities and the WHODAS summary scores is shown in Fig. 1. They are both negatively skewed and non-normal. The comparison of the two instruments can be found in ESM 1 Table S1. We found that the AQoL-4D utilities and the WHODAS total score had a moderate to strong correlation (r = − 0.68), all significant at the 5% level (ESM 1 Table S2), and two factors were identified in the EFA—physical health and psychosocial health (ESM 1 Table S3), which demonstrated good overlaps between the two instruments.

The distribution of the AQoL-4D utilities and the re-scaled WHODAS summary scores
Mapping results
Table 2 compares the goodness-of-fit statistics for the best five models. The first three columns show the predicted mean, the minimum and maximum values of AQoL-4D, while the last four columns report MAE, RMSE, ICC and the percentage of margin of error in predicted utility smaller than 0.03. All methods generally predicted the mean utility well, but MM and SVM overestimated it. The MM method in Model 2 (age and sex adjusted) had the lowest MAE value (MAE = 0.1325) and the second-highest percentage of margin of error smaller than 0.03 (18.78%). The MM method in Model 1, without adjusting to age and sex, had a similar MAE (0.1326) and the highest percentage of margin of error smaller than 0.03 (18.84%). The full results for all models and methods are presented in ESM Table S4.
The Lasso regression in Model 3 using the adaptive method and pairwise interactions of WHODAS responses performed better in predicting the upper and lower boundary of utility (− 0.04 to 1). Like other models, the predicted utilities smaller than − 0.04 were truncated to the AQoL-4D theoretical boundary − 0.04 before the goodness-of-fit calculation. This model and the SVM method in model 1 achieved the highest ICC (ICC = 0.667). The Lasso regression using the cross-validation method in Model 3 performed the best in achieving the lowest RMSE (RMSE = 0.1819). No machine learning techniques we used outperformed the best traditional econometric method with this sample.
Given that the MAE is our primary goodness-of-fit criteria, it is recommended that the MM estimator of Model 2 should be adopted for economic evaluations and other studies looking to predict average utilities for a group of participants.
Performance in people with different levels of disability restrictions
We examined how well the models performed in predicting the utility for people with different levels of disability restrictions using results from Sect. "Mapping results". The goodness-of-fit assessment (EMS1 Table S5a–e) showed that all models performed worse in predicting the utility for the group with profound or severe core restrictions (n = 294, observed mean utility = 0.423) compared to other severity levels, with MAE ranging from 0.1207 to 0.2583. Predicted values over-estimated utilities for this group by 0.069 to 0.165. Models performed better for the groups with mild restriction (n = 184) and no specific restrictions (n = 1955), with the lowest MAE in these groups.
Table 3 shows that although MM in Model 2 was found to perform the best overall, it did not outperform other models for the other subgroups except for those with no specific restriction (MAE = 0.1207). For the subgroup of profound and severe restrictions, GLM in model 2 with the log function and gamma family outperformed other models and methods (MAE = 0.1581, algorithm presented in ESM 1 Table S6). For the subgroups of moderate restrictions and school/ employment restrictions, the Beta method in model 2 outperformed the other methods (MAE = 0.1459 and 0.1435, respectively, algorithm presented in ESM 1 Table S7). For the subgroup with mild restrictions, the SVM technique in model 1 had the lowest MAE (MAE = 0.1262, STATA codes presented in ESM 1 File 1).
Figure 2 displays the between-group margins of error. The smallest between-group error was observed in the group with mild core restrictions (n = 184, observed between-group mean difference in utilities = − 0.084) and the group with school/employment restrictions (n = 473, observed between-group mean difference = − 0.147). The MM estimator had the smallest between-group error only in the group with profound restrictions (error = 0.069). For the subgroups of moderate core restrictions and school/employment restrictions, errors were the smallest when using Lasso regression and GLM, respectively. SVM generated the smallest average errors for the mild restriction group. It is also worth noting that the between-group errors are consistently positive across all subgroups for the MM method. However, they go both positive and negative for some other methods and techniques. More details on the prediction errors of the difference can be found in ESM1 Table S8.

Prediction errors in the average utility differences between different subgroups versus the no restriction group
Mapping algorithms
The final mapping algorithms were then developed using the full sample to increase the precision. The goodness-of-fit results of five selected models using the full study sample are presented in Table S9 in EMS1. The results show that the MM estimator using Model 2 remained the best in the traditional regression methods in achieving the lowest MAE. The error distributions of the predicted values using different methods and models are presented in Fig. S2 in ESM 1.
Table 4 shows the coefficients and standard errors for Model 2 using the MM estimator. The coefficients for Model 1 using MM estimator were also presented for users who do not collect data on age and sex. Based on the reported coefficient in Model 2 using the MM estimator, the predicted utility can be calculated as:
0.9270703-0.0304064*wd1_23-0.058266*wd1_4-0.100706*wd1_5-0.0502851*wd2_2-0.0765789*wd2_3-0.1402712*wd2_4-0.1924466*wd2_5-0.0220795*wd3_23-0.0343398*wd3_45-0.0211766*wd4_2-0.0519951*wd4_3-0.1219799*wd4_4-0.153431*wd4_5-0.0520421*wd5_2-0.0982621*wd5_3-0.1157922*wd5_4-0.1668916*wd5_5-0.0384057*wd6_2-0.0447633*wd6_345-0.0093647*wd7_23-0.0261744*wd7_4-0.0408746*wd7_5-0.0391969*wd8_2345-0.0454382*wd9_2-0.0977321*wd9_345-0.0529437*wd11_2-0.0904619*wd11_3-0.2493463*wd11_45-0.0404229*wd12_2-0.0664753*wd12_3-0.0855047*wd12_45-0.0005323*Age + 0.0092747*Sex
Each item in WHODAS is denoted by the number after "wd," while the subscripts denote the levels of the item. For instance, "wd2_2" refers to level 2 in item 2. Level 1 (i.e., None) is the reference category. If a male respondent aged 50 selects level 1 for 11 items, except that he experiences moderate difficulty in taking care of household responsibilities (that is he selects level 3 for item 2). Therefore, his utility will be 0.9270703–0.00765789–0.0005323*50 + 0.0092747 = 0.90207211. To establish a monotonic relationship between the items and utilities, we had to combine 13 levels into 10 different levels within several items resulting in 13 of the original level-item variables recombined into 10 variables.Footnote 2 The coefficients for these combined levels for the same item are the same. For example, level 2 and level 3 in Item 1 share the same coefficient of − 0.0583. Item 10 was excluded because it produced a positive coefficient even when all the levels were combined, and its coefficient for the combined item was statistically insignificant.
Discussion
This study investigated various methods and models to map the WHODAS 2.0-12 items to the AQoL-4D utilities, a generic and well-validated instrument whose utilities could be used in various settings. It allows the estimation of utilities when responses of only WHODAS are collected, which facilitates future economic evaluation of disability interventions.
The mapping study is conducted using people with disability in Australia aged 16–85. Therefore, the observed utility of this sample is lower than the Australian norm for AQoL (0.81, 95%CI 0.81–0.82), which is derived from the same survey we use. Notably, there is only one value set for AQoL-4D, which was developed in an Australian population. Therefore, at the moment, regardless of where the respondents are based globally, the identical Australian-specific value set is used. We understand that generalising the Australian preferences to other countries may not be ideal, but using the Australian value set does not suggest that the instrument could only be valid in the country of development. Previous research showed that between-country variations in value sets may stem from the types of respondent (e.g., proxy vs. self-reported), the methods (e.g., DCE vs. standard gamble), and the composition of the sample selected to do the value tasks [43]. Similar to Health Utilities Index, which developed the value set using only the Canadian sample but have been applied to research globally [44], we believe that AQoL-4D could be applied to broader than the Australian population.
The recommended mapping algorithm identified for a general disability population uses the MM estimator in Model 2, controlling for sex and age. The MAE of the cross-validation samples for this method is 0.1325, which is comparable with the ranges of other mapping studies whose MAE falls between 0.011 and 0.19 [19, 20, 33, 35]. Although the MM estimate overpredicted the utilities, our subgroup analysis showed that, unlike other methods, which over-predicted in some groups but under-predicted in others, the MM estimator consistently over-predicted the utilities across all the subgroups with different restriction levels (hence the prediction errors on the differences between different sub-groups could be minimised). Therefore, when using this recommended algorithm to estimate utilities in economic evaluations, the researchers should be aware that the actual utilities are possibly lower than the estimated ones for people with all levels of restrictions.
Economic evaluations focus on comparing a group receiving an intervention with a group that does not. As the MM estimator in Model 2 overpredicts utilities for all subgroups, the overpredicted errors would be offset when incremental utilities are calculated for comparisons between subgroups. Because the MM estimator generated consistently overestimates between-group differences, researchers should also be cautious while using MM in economic evaluations that compare subgroups with different restriction levels as the true differences may be smaller.
The machine learning technique did not outperform the traditional methods, even though the data-driven approaches allow for more flexibility. This is consistent with other mapping studies using machine-learning techniques [21, 22]. Additionally, controlling for age and sex did not enhance the performance of the machine learning technique, likely because the complexity of variable interactions is already taken into account. Some research has indicated that age and sex may not be statistically significant [34]. However, since age is statistically significant at the 5% level and some of our traditional models included the optimal MM model, we still include it in our algorithm. Sex is only significant at the 10% level in some of our models using traditional methods, but we have also included it because they are commonly included in mapping studies [19, 22, 34], can increase precision for our prediction, and we are not sure if the gender difference will affect the responses to WHOAS and AQoL-4D disproportionally in other data. It should also be noted that the sex variable in our data is a binary variable consisting of female and male. Newer surveys are likely to allow individuals to classify themselves in other categories. Future studies should explore whether gender classifications with more identity choices will impact the precision of the results.
We found that different models and methods predicted different subgroups better. We recommend using MM in model 2 to estimate utilities for a population with different disability levels or people with disability but no specific restrictions. GLM with the log function and gamma family, Beta regression method, and SVM in model 1 are recommended for sensitivity analysis if the sample is concentrated on people with profound/severe, moderate or school/employment, and mild restrictions, respectively. Researchers could use the algorithms and STATA codes provided in the ESM to perform additional sensitivity analysis.
Unique items were identified in our concept mapping process for WHODAS and AQoL-4D, and these items are more likely to require combining levels to achieve monotonic correlation. For example, items related to cognition that were only asked in WHODAS required level combining and an item in WHODAS asking about dealing with unknown people was dropped due to positive correlation. This suggests that the relationship question in WHODAS was focused on a different type of relationship compared to AQoL-4D, which emphasises relationships with friends and family. It highlights the importance of considering the algorithm’s applicability when evaluating interventions.
Several limitations to this study should be acknowledged. The model performance of the study was validated using five-fold cross-validation but with data from the same study sample. Since the mapping is a data-driven exercise, the choice of response sample could affect the calibration of the mapping algorithm. Ideally, in the future, validation will also be possible using an external dataset. The second limitation of the study is that the predicted AQoL-4D utilities under-predict the highest utilities. This is a commonly reported limitation in many mapping studies [33, 35]. However, because the algorithm consistently under-predicts the highest utility in each subgroup, the issue may be attenuated when comparing different groups in an economic evaluation study. The last limitation was that information about the disability types (e.g., physical, psychosocial) was not in the data. However, given the large sample size, we saw many variations in both the source and target instruments, and we were able to perform a subgroup analysis based on the restriction level of disability.
The results from this mapping study indicate that it is reasonable to map WHODAS onto the AQoL-4D utilities. The availability of this mapping algorithm will facilitate future economic evaluation for disability interventions when only the WHODAS is used.
Notes
Between group margins of error = (the predicted average utility value of the restriction subgroup—the predicted average utility value of the no restriction subgroup)—(the observed utility value of the restriction subgroup—the observed utility value of the no restriction subgroup).
Level 2 = Level 3 in item1, 3, 7; level 4 = level 5 in item 3, 11, 12; level 3 = level4 = level 5 in item 6, 9; level 2 = level 3 = level 4 = level 5 in item 8.
References
Elith, J., Leathwick, J. R., & Hastie, T. (2008). A working guide to boosted regression trees. Journal of Animal Ecology., 77(4), 802–813.
EuroQol Group. (1990). EuroQol-a new facility for the measurement of health-related quality of life. Health Policy, 16(3), 199–208. https://doi.org/10.1016/0168-8510(90)90421-9
Hawthorne, G., Richardson, J., & Osborne, R. (1999). The Assessment of Quality of Life (AQoL) instrument: A psychometric measure of health-related quality of life. Quality of Life Research, 8(3), 209–224. https://doi.org/10.1023/a:1008815005736
Longworth, L., & Rowen, D. (2013). Mapping to obtain EQ-5D utility values for use in NICE health technology assessments. Value in Health, 16(1), 202–210. https://doi.org/10.1016/j.jval.2012.10.010
National Institute for Clinical Excellence. (2008). Guide to the methods of technology appraisal. https://www.nice.org.uk/Media/Default/About/what-we-do/NICE-guidance/NICE-technology-appraisals/technology-appraisal-processes-guide-apr-2018.pdf
Langley, P. C. (2017). Dreamtime: Version 5.0 of the Australian Guidelines for Preparing Submissions to the Pharmaceutical Benefits Advisory Committee (PBAC). INNOVATIONS in Pharmacy, 8(1). https://doi.org/10.24926/iip.v8i1.485
Papaioannou, D., Brazier, J., & Parry, G. (2011). How valid and responsive are generic health status measures, such as EQ-5D and SF-36, in schizophrenia? A systematic review. Value in Health, 14(6), 907–920. https://doi.org/10.1016/j.jval.2011.04.006
Chen, G, P. D., Richardson J, Sia K-L, Jackson A, & Harris A. (2017). Rapid review of wellbeing measures to assist disability support priority setting. Retrieved from [Contact author].
Ćwirlej-Sozańska, A., Sozański, B., Kotarski, H., Wilmowska-Pietruszyńska, A., & Wiśniowska-Szurlej, A. (2020). Psychometric properties and validation of the Polish version of the 12-item WHODAS 2.0. BMC Public Health, 20(1), 1–10. https://doi.org/10.1186/s12889-020-09305-0
Holmberg, C., Gremyr, A., Torgerson, J., & Mehlig, K. (2021). Clinical validity of the 12-item WHODAS-2.0 in a naturalistic sample of outpatients with psychotic disorders. BMC Psychiatry, 21(1), 1–11.
Park, S. H., Demetriou, E. A., Pepper, K. L., Song, Y. J. C., Thomas, E. E., Hickie, I., Glozier, N., & Guastella, A. J. (2019). Validation of the 36-item and 12-item self-report World Health Organization Disability Assessment Schedule II (WHODAS-II) in individuals with autism spectrum disorder. Autism Research, 12(7), 1101–1111. https://doi.org/10.1002/aur.2115
Silva, C., Coleta, I., Silva, A. G., Amaro, A., Alvarelhão, J., Queirós, A., & Rocha, N. (2013). Adaptation and validation of WHODAS 2.0 in patients with musculoskeletal pain. Revista de Saúde Pública, 47, 752–758. https://doi.org/10.1590/S0034-8910.2013047004374
Silveira, C., Souza, R. T., Costa, M. L., Parpinelli, M. A., Pacagnella, R. C., Ferreira, E., Mayrink, J., Guida, J., Sousa, M., Say, L., Chou, D., Filippi, V., Barreix, M., Barbour, K., Firoz, T., von Dadelszen, P., & Cecatti, J. (2018). Validation of the WHO Disability Assessment Schedule (WHODAS 2.0) 12-item tool against the 36-item version for measuring functioning and disability associated with pregnancy and history of severe maternal morbidity. International Journal of Gynecology & Obstetrics, 141, 39–47. https://doi.org/10.1002/ijgo.12465
Younus, M. I., Wang, D.-M., Yu, F.-F., Fang, H., & Guo, X. (2017). Reliability and validity of the 12-item WHODAS 2.0 in patients with Kashin-Beck disease. Rheumatology international, 37(9), 1567–1573. https://doi.org/10.1007/s00296-017-3723-4
Petrou, S., Rivero-Arias, O., Dakin, H., Longworth, L., Oppe, M., Froud, R., & Gray, A. (2015). Preferred reporting items for studies mapping onto preference-based outcome measures: The MAPS statement. International Journal of Technology Assessment in Health Care, 31(4), 230–235. https://doi.org/10.1017/S0266462315000379
Lokkerbol, J., Wijnen, B. F., Chatterji, S., Kessler, R. C., & Chisholm, D. (2021). Mapping of the World Health Organization’s Disability Assessment Schedule 20 to disability weights using the Multi-Country Survey Study on Health and Responsiveness. International Journal of Methods in Psychiatric Research, 30(3), e1886.
Üstün, T. B., Chatterji, S., Villanueva, M., Bendib, L., Çelik, C., Sadana, R., Valentine, N., Oritz, J., Tandon, A., & Salomon, J. (2001). WHO multi-country survey study on health and responsiveness. World Health Organization.
Chen, G., Khan, M. A., Iezzi, A., Ratcliffe, J., & Richardson, J. (2016). Mapping between 6 multiattribute utility instruments. Medical Decision Making, 36(2), 160–175. https://doi.org/10.1177/0272989X15578127
Sweeney, R., Chen, G., Gold, L., Mensah, F., & Wake, M. (2020). Mapping PedsQLTM scores onto CHU9D utility scores: Estimation, validation and a comparison of alternative instrument versions. Quality of Life Research, 29(3), 639–652. https://doi.org/10.1007/s11136-019-02357-9
Brazier, J. E., Yang, Y., Tsuchiya, A., & Rowen, D. L. (2010). A review of studies mapping (or cross walking) non-preference based measures of health to generic preference-based measures. The European Journal of Health Economics, 11(2), 215–225. https://doi.org/10.1007/s10198-009-0168-z
Gao, L., Luo, W., Tonmukayakul, U., Moodie, M., & Chen, G. (2021). Mapping MacNew Heart Disease Quality of Life Questionnaire onto country-specific EQ-5D-5L utility scores: A comparison of traditional regression models with a machine learning technique. The European Journal of Health Economics, 22(2), 341–350. https://doi.org/10.1007/s10198-020-01259-9
Aghdaee, M., Parkinson, B., Sinha, K., Gu, Y., Sharma, R., Olin, E., & Cutler, H. (2022). An examination of machine learning to map non-preference based patient reported outcome measures to health state utility values. Health Economics, 31(8), 1525–1557. https://doi.org/10.1002/hec.4503
Almazán-Isla, J., Comín-Comín, M., Damián, J., Alcalde-Cabero, E., Ruiz, C., Franco, E., Martín, G., Larrosa-Montañés, L., de Pedro-Cuest, J., & Group, D.-A.R. (2014). Analysis of disability using WHODAS 2.0 among the middle-aged and elderly in Cinco Villas, Spain. Disability and Health Journal, 7(1), 78–87. https://doi.org/10.1016/j.dhjo.2013.08.004
Axelsson, E., Lindsäter, E., Ljótsson, B., Andersson, E., & Hedman-Lagerlöf, E. (2017). The 12-item Self-Report World Health Organization Disability Assessment Schedule (WHODAS) 2.0 administered via the internet to individuals with anxiety and stress disorders: a psychometric investigation based on data from two clinical trials. JMIR Mental Health, 4(4), e7497. https://doi.org/10.2196/mental.7497
Kim, J.-I., Long, J. D., Mills, J. A., Downing, N., Williams, J. K., & Paulsen, J. S. (2015). Performance of the 12-item WHODAS 2.0 in prodromal Huntington disease. European Journal of Human Genetics, 23(11), 1584–1587. https://doi.org/10.1038/ejhg.2015.11
Veiga, B., Pereira, R. A. B., Pereira, A. M. V. B., & Nickel, R. (2016). Evaluation of functionality and disability of older elderly outpatients using the WHODAS 2.0. Revista Brasileira de Geriatria e Gerontologia, 19, 1015–1021. https://doi.org/10.1590/1981-22562016019.150053
Doupe, P., Faghmous, J., & Basu, S. (2019). Machine learning for health services researchers. Value in Health, 22(7), 808–815. https://doi.org/10.1016/j.jval.2019.02.012
Üstün, T. B., Kostanjsek, N., Chatterji, S., & Rehm, J. (eds). (2010). Measuring health and disability: Manual for WHO disability assessment schedule WHODAS 2.0: World Health Organization. https://apps.who.int/iris/handle/10665/43974
Richardson, J., Chen, G., Iezzi, A., & Khan, M. A. (2011). Transformations between the Assessment of Quality of Life AQoL instruments and test-retest reliability. Centre for Health Economics, Monash University.
Gamst-Klaussen, T., Lamu, A. N., Chen, G., & Olsen, J. A. (2018). Assessment of outcome measures for cost–utility analysis in depression: Mapping depression scales onto the EQ-5D-5L. BJPsych Open, 4(4), 160–166. https://doi.org/10.1192/bjo.2018.21
Lamu, A. N., Chen, G., Gamst-Klaussen, T., & Olsen, J. A. (2018). Do country-specific preference weights matter in the choice of mapping algorithms? The case of mapping the Diabetes-39 onto eight country-specific EQ-5D-5L value sets. Quality of Life Research, 27, 1801–1814. https://doi.org/10.1007/s11136-018-1840-5
Taherdoost, H., Sahibuddin, S., & Jalaliyoon, N. (2022). Exploratory factor analysis; concepts and theory. Advances in applied and pure mathematics, 27, 375–382. hal-02557344
Catchpool, M., Ramchand, J., Hare, D. L., Martyn, M., & Goranitis, I. (2020). Mapping the Minnesota Living with Heart Failure Questionnaire (MLHFQ) onto the Assessment of Quality of Life 8D (AQoL-8D) utility scores. Quality of Life Research, 29(10), 2815–2822. https://doi.org/10.1007/s11136-020-02531-4
Chen, G., Stevens, K., Rowen, D., & Ratcliffe, J. (2014). From KIDSCREEN-10 to CHU9D: Creating a unique mapping algorithm for application in economic evaluation. Health and Quality of Life Outcomes, 12(1), 1–11. https://doi.org/10.1186/s12955-014-0134-z
Chen, G., Tan, J. T., Ng, K., Iezzi, A., & Richardson, J. (2014). Mapping of Incontinence Quality of Life (I-QOL) scores to Assessment of Quality of Life 8D (AQoL-8D) utilities in patients with idiopathic overactive bladder. Health and Quality of Life Outcomes, 12(1), 133. https://doi.org/10.1186/s12955-014-0133-0
Kaambwa, B., Chen, G., Ratcliffe, J., Iezzi, A., Maxwell, A., & Richardson, J. (2017). Mapping between the Sydney Asthma Quality of Life Questionnaire (AQLQ-S) and five multi-attribute utility instruments (MAUIs). PharmacoEconomics, 35(1), 111–124. https://doi.org/10.1007/s40273-016-0446-4
Ranstam, J., & Cook, J. A. (2018). LASSO regression. Journal of British Surgery, 105(10), 1348–1348.
Smola, A. J., & Schölkopf, B. (2004). A tutorial on support vector regression. Statistics and Computing, 14, 199–222.
Willmott, C. J., & Matsuura, K. (2005). Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Climate Research, 30(1), 79–82.
Mpundu-Kaambwa, C., Chen, G., Russo, R., Stevens, K., Petersen, K. D., & Ratcliffe, J. (2017). Mapping CHU9D utility scores from the PedsQLTM 4.0 SF-15. PharmacoEconomics, 35(4), 453–467. https://doi.org/10.1007/s40273-016-0476-y
Sullivan, P. W., & Ghushchyan, V. (2006). Mapping the EQ-5D index from the SF-12: US general population preferences in a nationally representative sample. Medical Decision Making, 26(4), 401–409. https://doi.org/10.1177/0272989X06290496
Lambe, T., Frew, E., Ives, N. J., Woolley, R. L., Cummins, C., Brettell, E. A., Barsoum, N., & Webb, N. (2018). Mapping the Paediatric Quality of Life Inventory (PedsQL™) generic core scales onto the Child Health Utility Index–9 Dimension (CHU-9D) score for economic evaluation in children. PharmacoEconomics, 36(4), 451–465. https://doi.org/10.1007/s40273-017-0600-7
Kwon, J., Freijser, L., Huynh, E., Howell, M., Chen, G., Khan, K., et al. (2022). Systematic review of conceptual, age, measurement and valuation considerations for generic multidimensional childhood patient-reported outcome measures. PharmacoEconomics, 40(4), 379–431. https://doi.org/10.1007/s40273-021-01128-0
Horsman, J., Furlong, W., Feeny, D., & Torrance, G. (2003). The Health Utilities Index (HUI®): Concepts, measurement properties and applications. Health and Quality of Life Outcomes, 1(1), 1–13. https://doi.org/10.1186/1477-7525-1-54
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. Centre for Research Excellence of Disability and Health, APP1116385, Bernice Hua Ma.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have not disclosed any conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, B.H., Chen, G., Badji, S. et al. Mapping the 12-item World Health Organization disability assessment schedule 2.0 (WHODAS 2.0) onto the assessment of quality of life (AQoL)-4D utilities. Qual Life Res 33, 411–422 (2024). https://doi.org/10.1007/s11136-023-03532-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11136-023-03532-9